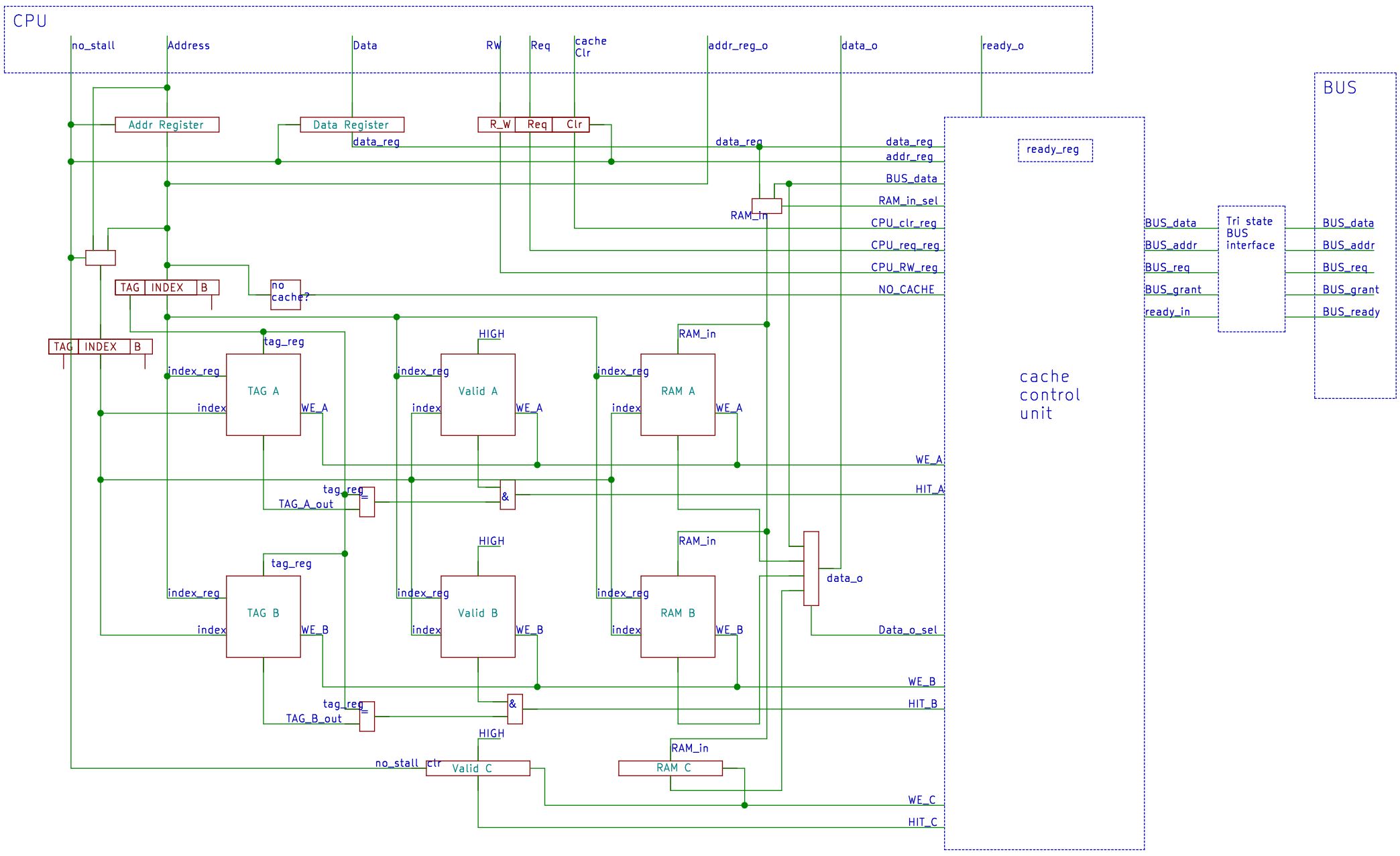
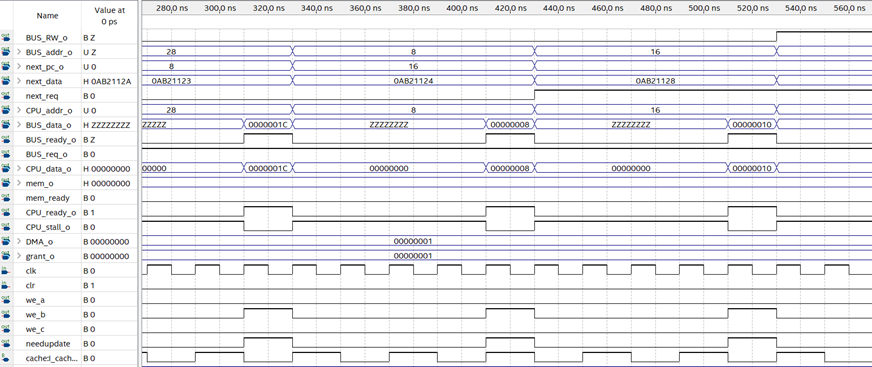
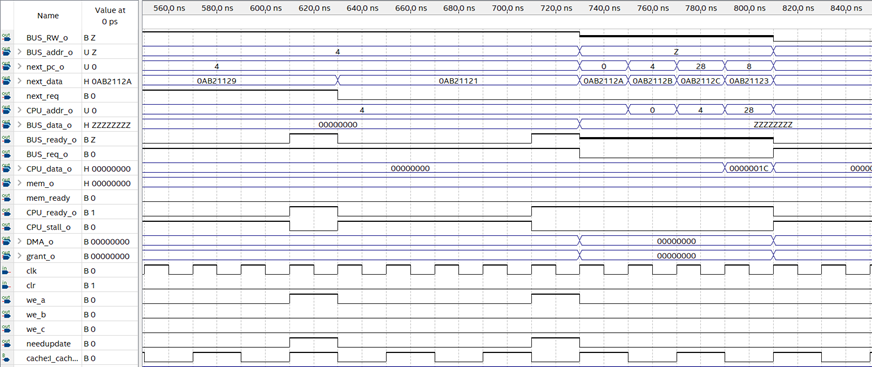
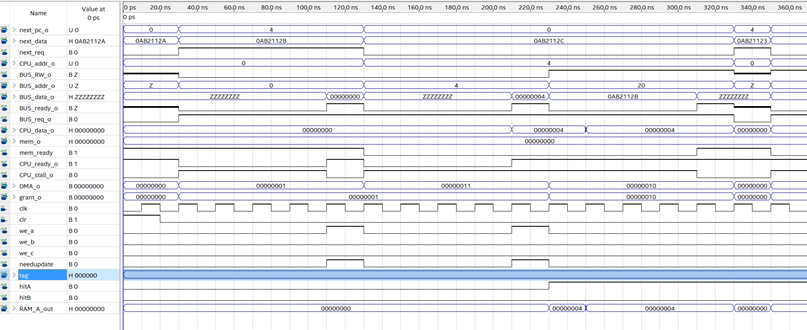
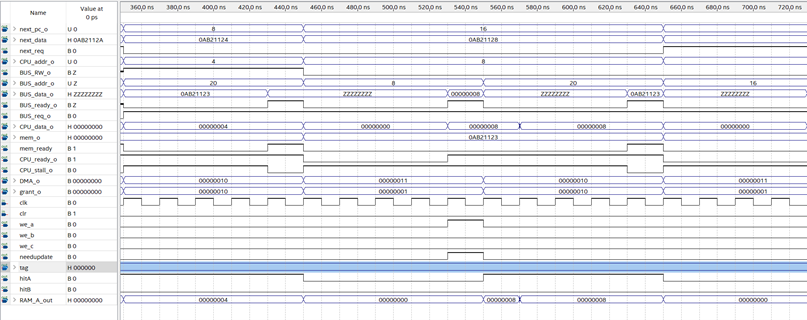
控制单元是整个CPU的核心,他控制着CPU内各个功能部件以及流水线的运作。
本系统中控制单元的功能需求也是随着设计实现工作的进展一点一点增加的,我先后在控制单元中添加了分支预测、多周期指令、cache同步和自修改代码、精确中断和异常等复杂的控制功能,希望在保持设计简洁的同时能够给程序员带来更多便利,最大限度的屏蔽微架构在程序层面的影响。
经过一个多月的工作,我所设计的控制单元初版已经完成(control_unit.v),我将在这篇文章中详细记述我的设计决策。
设计中最复杂的部分是实现对流水线正确地控制。分支预测失败、多周期指令、自修改代码、异常中断和流水线冲突很多是可能同时发生的,因此要想实现对流水线的正确控制,必须仔细分析这其中的关系,以确定当他们同时发生时处理器的行为。这项分析工作占据了我这个月大部分时间,最终我得以找到一套合理的处理逻辑来解决流水线的控制,这也将是这篇文章的重点内容。
设计目标
- 硬线逻辑实现
- 分支预测支持
- 多周期指令支持(按字节,按半字写入内存)
- cache同步和自修改代码支持
- 精确中断和异常支持
- 正确高效处理流水线冲突(流水线暂停和数据旁路,未来考虑增加对乱序指令的支持(初步的超标量))
- 预留性能检测模块支持
实现
接口定义
依照惯例,先描述控制单元与其他部件的接口。
与IR(指令寄存器)的连接
1 | input canceled; |
IR是IF级与ID级之间的流水线寄存器,如果该指令在预取阶段(IF)就被撤销,canceled位会被设置为高电平。
instruction会被拆分成几段供译码器使用:
1 | wire [5:0] op = canceled ? 6'b0 : instruction [31:26]; |
其中rs、rt用作两个寄存器号输出给寄存器堆做索引。
与寄存器堆的连接
除rs、rt输出给寄存器堆做索引外,CU还需要将寄存器堆的两个数据输出作为输入:
1 | output [4:0] rs ; |
向下一级流水线寄存器的信号输出
数据输出
1 | output [31:0] da,db,imm; |
da,db和imm是三个操作数,其中imm根据sign信号进行了符号扩展。
TargetReg是当前指令的目标寄存器号。
控制信号
这些信号控制着ID级后的功能部件:
1 | output RegWrite,M2Reg,MemReq,MemWrite,AluImm,ShiftImm,link,slt; |
RegWrite:当指令需要写入寄存器堆时,该信号为高电平。
M2Reg:当指令需要从内存读取数据并写入寄存器堆时(load指令),该信号为高电平。
MemReq:当指令需要请求内存时,该信号为高电平,这个信号在MEM级与Dcache的请求信号相连。
MemWrite:当指令需要写入内存时(store指令),该信号为高电平。
AluImm:该信号为高电平表示当前指令在使用ALU时,其中的一个操作数时立即数。该信号控制ALU数据输入接口B前的多路器。
ShiftImm:该信号为高电平表示当前的位移指令的位移量是立即数。该信号控制ALU数据输入接口A前的多路器。
link:该信号表示当前信号是一个jump and link指令,他将修改EXE级的输出:将ALU的输出设定为PC+4,并将目标寄存器号设定为31.
slt: 该信号为高点并表示当前指令是一个条件测试指令(stl等)。
sign:该信号用于指示EXE级计算是否有溢出异常,并且用于CU内部控制立即数的符号扩展。
StoreMask,LoadMask,B_HW,LoadSign四个信号用于实现按半字、按字节存取:
StoreMask:该信号为高电平表示需要MEM级在写入前使用mask。
LoadMask:该信号为高电平表示需要MEM级在读出后使用mask。
B_HW:该信号控制mask的长度是8位还是16位(字节或者半字)。
LoadSign:该信号控制按字节或按半字读取时的符号扩展。
AluFunc:AluFunc是根据指令生成的ALU function code,编码如下:
| code | func | code | func | code | func | code | func |
|---|---|---|---|---|---|---|---|
| 0000 | ADD | 0100 | AND | 1000 | SLL | 1100 | MULT |
| 0001 | SUB | 0101 | XOR | 1001 | LUI | 1101 | MULTU |
| 0010 | CLZ | 0110 | OR | 1010 | SRL | 1110 | DIV |
| 0011 | CLO | 0111 | NOR | 1011 | SRA | 1111 | DIVU |
流水线控制
两个cache的ready信号输入,标志着处理器是否可以执行下一条指令:
1 | input I_cache_R, D_cache_R; |
根据这两个ready信号输入,可以生成CPU_stall信号,它既参与ID级内部的控制,也作为控制信号输出给其他各级:
1 | output CPU_stall; |
对于IF和ID级,多周期指令和流水线数据相关冲突会引起额外的暂停,Stall_IF_ID与CPU_stall一起控制IF和ID级的流水线寄存器的写入:
1 | output Stall_IF_ID; |
控制单元与分支预测器的接口如下:
1 | output BP_miss; |
BP_miss为高电平标志当前分支预测结果错误,流水线需要退回。
is_branch为高电平表示当前ID级的有效指令是一个跳转指令。
do_branch为高电平表示若当前ID级的有效指令是一个跳转指令,则当前跳转指令的计算结果是跳转发生。
V_target为高电平表示若当前ID级的有效指令是一个跳转指令,则当前跳转指令的跳转目标是可变的(由寄存器读出)。
上述四个指令将指导分支预测器更新维护其跳转历史表。
BP_target为分支预测器的输出,是分支预测器的预测结果,该数据用于计算next PC。
1 | output reg [31:0] next_PC; |
PC寄存器中的数据在每一级流水线寄存器中都要寄存,用于追踪当前级执行的指令地址,以实现复杂的流水线控制:
1 | input [31:0] PC, ID_PC, EXE_PC, MEM_PC; |
除ID级异常和异常号由CU生成外,其余各级的异常和异常号均由各级直接输入给CU:
1 | input exc_IF, exc_EXE,exc_MEM; |
每级异常号均有3位,即每级支持7种异常。
由CU产生各级的废弃信号:
1 | output reg ban_IF,ban_EXE,ban_MEM; |
与中断控制器的连接:
1 | input int_in; |
SOC中,中断控制器负责控制外部中断的排队。它将排队成功的请求编码成20位的中断向量通过int_num送给CU,并将外部中断信号int_in置为高电平,等待CU决定接受中断请求时,CU会将int_ack置为高电平一个周期,中断控制器在收到int_ack后应立即撤掉当前中断请求。
每级的3位异常号和20位的中断向量一起编码,在响应异常或中断时存储在CAUSE寄存器中,编码格式如下:
| 31-29 | 28-26 | 25 -23 | 22-20 | 19 — 0 |
|---|---|---|---|---|
| IF | ID | EXE | MEM | interrupt |
处理流水线数据相关的暂停和数据旁路需要EXE级和MEM级的控制信号,因此要将下列信号从EXE级和MEM级抽出,输入CU:
1 | input M_m2reg,M_RegWrite,E_m2reg,E_RegWrite; |
M_m2reg,M_RegWrite,E_m2reg,E_RegWrite对应MEM级和EXE级的m2reg和RegWrite信号。
M_TargetReg和E_TargetReg用于和当前ID级指令的源寄存器号比较,以发现数据相关冒险。
E_AluOut,M_AluOut,M_MemOut用作数据旁路,将这些未执行完的指令的中间结果直接拿到ID级使用。
CU还支持对自修改代码的同步,因此需要当前MEM级正准备修改的内存地址:
1 | input [31:0] M_MemAddr; |
时钟和清零信号
1 | input clk,clr; |
功能实现
对于CU实现的描述我将按照先简单后复杂,先个体再整体的顺序描述,先说一说每个功能单元的设计,然后再说关于他们协同工作的设计。
指令译码
指令译码是CU中最容易实现的部分,它直接将分片过的指令与指令模板进行比对。如果未来要支持其他的指令,则需要直接修改这部分设计。
首先将Register类型的指令挑出来,便于后续指令译码:
1 | //the instruction is R-type if the op code is 000000(SPECIAL), 011100(SPECIAL2) |
译码相关指令非常简单。R type指令:
1 | //R_type |
I type指令:
1 | //I_type |
J type指令:
1 | //J_type |
每个支持的指令对应一个i_xxx信号,这些信号同一时间只有可能有一个为高电平。若所有这些信号均为低电平则说明当前指令未尚不支持的指令,CU会产生ID级异常:
1 | //for instructions which are not implemented. |
多周期指令支持
为什么要支持多周期指令?有些指令是无法在一个周期内执行完的,比如store byte和store half-word。我所设计的这个计算机系统内存是按字(4字节)索引的,因此要想实现SB和SHW指令,至少需要两个周期,第一个周期读取要写入的字,第二个周期修改要修改的字节或半字并写入内存。如果处理器不直接提供这种按字节或按半字存取的指令,就要使用汇编器产生的伪指令,这样很难保证两条伪指令之间的原子性,因此我决定在CU中增加对多周期指令的支持。具体的做法是设置一个微程序计数器(microprogram counter uPC),并且在译码单元中对每条指令所需要的周期数进行记录(cycle),当upc小于cycle时,说明指令尚未执行完,ID级和IF级的流水线寄存器会暂停,而CU内部根据当前指令和upc的值生成对应多周期指令某一周期所需要的控制信号。这个做法与传统的使用微程序的控制单元有一定的不同。
1 | //cycle implies number of cycles for a instruction |
微程序计数器在指令完成后清零,在CPU stall或由于数据相关引起的IFID级暂停时暂停更新,其他情况微程序计数器加一:
1 | always @(posedge clk) |
CU中有多个stall信号,他们是整个系统可以协同工作的关键。我为数据相关引起的IF和ID级暂停引入了单独的stall信号(stall_RAW),为尚未完成的多周期指令引入了单独的stall信号(ins_done),为由于cache未准备好引起的整个CPU暂停引入信号CPU_stall。
IF和ID级的暂停信号Stall_IF_ID由stall_raw和is_done共同产生:
1 | assign Stall_IF_ID = ~ins_done | Stall_RAW; |
关于upc的更新的条件需要特别地说明。数据相关有可能是某一个微指令引起的,因此当发生数据相关流水线需要暂停时,当前的微指令(或指令)也被暂停,因此此时不应更新upc。当Cache尚未准备好时,整个CPU的状态不发生变化,因此CU内部的所有寄存器在CPU_stall时均不发生改变。
功能部件控制信号生成
CU将所有需要的控制信号直接生成,各级的功能模块的控制信号通过各级流水线寄存器将后续各级需要的信号向后传递。
对于在WB级需要写入寄存器的指令,RegWrite信号为高电平:
1 | //RegWrite is High when instruction needs to write registers. |
对于所有需要请求D cache(内存)的指令,无论读写,MemReq信号为高电平,若当前指令不需要读写D cache,MemReq为低电平,D cache可以根据该信号直接生成ready信号跳过对内存的访问。对于SB和SHW指令,他们的两个周期都需要访存。
1 | //Memory request signal is active when the instruction needs to access the memory, |
MemWrite指示当前指令是否需要写入内存。对于SW指令和SB、SHW的第二个周期(按字节、半字写入第一个周期读取相应的存储字,第二个周期在mask后写入像一个的存储字),该信号为高电平。
1 | //Memory Write is active when the instruction is a store operate. |
AluImm控制ALU数据输入端口B前的多路器,当AluImm为高电平时,端口B选择经ID级符号扩展后的立即数作为ALU端口B的输入。对于所有使用立即数的算术指令,该信号为高电平。
1 | //AluImm indicates that operand B of ALU is an immediate operand, it is used at EXE |
ShiftImm控制ALU数据输入端口A前的多路器。对于位移指令,位移量的输入在ALU的端口A,被位移的操作数输入于ALU端口B,因此对于使用立即数的位移指令该信号为高电平。
1 | //ShiftImm is used at EXE stage. For shift word operations, rs is 5-bit zeros, and |
link信号用于跳转并连接指令,他作用与EXE级ALU输出端口后的多路器。当他为高电平时,ALU的输出被绕过,取而代之的是EXE_PC+4,并把目标寄存器号覆盖为31,在MEM和WB级完成连接的功能,将当前跳转指令的下一跳指令地址(返回地址)放入约定好的寄存器31。
1 | //link signal is for branch and link operations. This signal is used at EXE stage, |
slt信号用于set less than指令,ALU中没有实现比较功能,因此EXE级引入了一个额外的比较器。当slt信号为高电平时,EXE级的输出选择比较器的输出。
1 | //slt is for set less than operations. When this signal is HIGH, the corresponding |
sing信号控制指令中的立即数是否需要符号扩展。它不光在ID级用来计算跳转的目标地址,也用在EXE级控制是否产生溢出异常,为set less than指令选择正确的比较器。
1 | assign sign = i_bgez|i_bgezal|i_bltz|i_bltzal|i_beq|i_bne|i_blez|i_bgtz|i_addi|i_slti |
下面这组信号用于控制按字节、半字读写。
StoreMask通知MEM级使用mask处理将要写入的数据,因此当store byte/half-word处于第二周期时,StoreMask为高电平:
1 | //StoreMask select the masked value as the input of memory. This signal is active |
LoadMask通知MEM级在读出数据时使用mask,load byte/half-word指令不需要第二个周期。
1 | //LoadMask select the masked value as the output of MEM stage. This signal is active |
B_HW用于为load/store byte/half-word这些指令选择正确的mask长度。
1 | //for load/store byte/half word, B_HW is HIGH for load/store half word, and LOW for |
LoadSign为单独为load byte/half-word引入的符号扩展标志。
1 | //This is for load byte/half word signed instructions. |
CU会根据译码结果选择正确的目标寄存器号。大部分指令使用rd作为目标寄存器,有些指令则使用rt作为目标寄存器号,对于这些指令TargetRegSel为高电平,这个信号作用于CU内部并控制一个多路器将结果用TargetReg输出:
1 | //Most instructions use rd as target register, but some use rt as target. |
最后,CU还需要生成合适的ALU控制码AluFunc:
1 | always @ (*) begin |
操作数
立即数截取
从IR中获取的立即数要根据指令的不同进行符号扩展:
1 | //sign extension controlled by sign signal. |
数据旁路和流水线暂停
寄存器中存储的操作数可能会受到数据相关冒险的影响,因此为其设计数据旁路。
数据旁路由三种情况:
- 若当前ID级的指令所使用的源寄存器与当前EXE级中的目标寄存器相同,且EXE级不是load指令,则直接将EXE级的结果作为当前ID级的源操作数。
- 若当前ID级指令所使用的源寄存器与MEM级的目标寄存器相同,且MEM级不是load指令,则直接将从EXE级传来的ALU的结果作为当前ID级的源操作数。
- 若当前ID级指令所使用的源寄存器与EXE级中的目标寄存器相同,且EXE级的指令是一个load指令(E_m2reg为高电平),这意味着IF和ID级必须等待一个周期,并且当前的ID级指令必须被废弃,这样一个周期以后,就可以将MEM读出的结果作为ID级指令的源操作数。
数据旁路和由于数据相关引起的流水线暂停的相关逻辑如下:
指令的两个源寄存器均有可能发生数据相关冲突,所以首先要将可能受影响的指令列出来。need_rs为高电平表示当前ID级的指令需要rs作为源寄存器;need_rt为高电平表示当前ID级的指令需要rt作为源寄存器。
1 | //need_rs is active when a instruction needs rs as operand. |
如果发生第三种情况,要暂停IF、ID级流水线一个周期。为此引入一个独立的stall信号:
1 | wire Stall_RAW = E_RegWrite & E_m2reg & (E_TargetReg!=0) |
在流水线暂停的同时,还要将当前ID级的指令废弃,为此引入一个独立的废弃信号:
1 | wire ban_ID_RAW = Stall_RAW; |
正如前面所说,整个系统内有多个暂停和废弃信号,他们是系统各个部件可以协同工作的关键,我将在流水线控制部分详细介绍这些信号的层级和作用。
数据旁路主要实现了上述三种情况,在寄存器堆和下一级流水线寄存器间增加一个多路器,最终结果为regA、regB。
1 | reg [31:0] regA, regB; |
对于regB的数据旁路跟regA一样,这里不再赘述。
流水线控制
流水线的控制是CU要处理的核心问题。因为很多种特殊情况可能同时发生,因此这部分的控制需要深入的分析。
在这里我首先列举系统中可能出现的特殊情况:
- IF级:分支预测失败、自修改代码同步、IF级异常(地址错误、以及引入分页后的TLB异常等)
- ID级:数据相关冲突、多周期指令、自修改代码同步、IF级异常(未实现的指令、syscall)
- EXE级: 自修改代码同步、EXE级异常(溢出)
- MEM级: MEM级异常(地址错误、TLB异常等)
- 外部中断
针对这些流水线的特殊情况,控制逻辑设计有一个原则 ,就是尽量想办法把复杂的问题简单化,并且能够尽可能的分析他们之间的关系和影响,然后确定处理器的行为。
根据这个原则,外部中断来自处理器外部,因此可以对外部中断的响应设置条件,让处理器在合适的时机响应中断,这样可以大大简化整个流水线控制逻辑。因此我的处理器响应中断的条件是处理器处在“正常”状态。所谓的正常状态,是指没有任何其他的异常、流水线不能有任何暂停、同时ID级当前处理的指令不能是mtc0指令。设置第一个条件是因为异常来自于CPU内部,之前的文章也有提到,如果不及时处理这些来自于内部的异常,处理器会丢失正确的顺序;设置第二个条件的原因是因为我所设计的中断控制器在收到中断响应信号后的下个周期就会撤销当前中断请求,如果发生中断响应时处理器整个或者部分处于暂停状态,在中断控制器收到中断响应信号并将中断请求撤销时,处理器因为停顿没有将中断处理程序的地址载入PC,这就导致错过了中断请求;设置第三个条件的原因是,mtc0可以修改status寄存器,而status寄存器中最低位作为中断屏蔽使用,为了确定处理器的行为,我设置这个条件,只有当mtc0执行结束、status寄存器的值稳定后,才可以响应中断。
1 | //When to response to an interrupt request |
人为的对外部中断响应加以限制不会造成功能的缺失,因为我们永远无法预测外部中断到来的时机,早一会儿晚一会儿处理它不会对运行结果产生任何影响,但这样做可以简化控制逻辑的设计,在接下来的分析中可以完全撇开外部中断对CPU的影响。
对于其他的特殊情况的处理就没有那么幸运了,他们均产生于处理器内部,因此我们无法让处理器等待,一旦发生这些情况必须立即处理。问题是如果他们中的多个同时发生怎么办?他们可能同时发生吗?他们的确可能同时发生,例如数据相关冲突就可以和多周期指令同时发生,某个多周期指令的某一周期需要的源寄存器是上一指令的目标寄存器。再例如分支预测失败和数据相关也可以同时发生,ID级是一个jump register指令,而该指令的源寄存器是前面代码的目标寄存器。再例如由MEM级的写入请求产生的自修改代码可以和任何一种异常同时发生。
从对不同级的流水线异常来看,MEM级最简单而IF级和ID级最复杂。无论这些异常如何同时发生,有一点是需要明确的,就是一旦CPU决定处理这个异常,他所在的级以及这几级之前的流水线中的指令都要被废弃。比如说,如果MEM级发生了异常,CPU会将MEM级以及MEM级以前的所有级的指令都废弃掉,哪怕这些级中可能同时存在异常。换句话说,更深层级流水线产生的异常优先级更高,低层级的异常可以被高层级的异常覆盖。这一原则给控制逻辑的设计提供了思路,一种异常可以覆盖另一种异常,这种处理思路不但可以用在不同层级的异常中,也可以用在某一级可能同时发生的不同异常中。对于不同级可能同时发生的异常,为更深的流水线级异常赋予更高优先级是显而易见且正确的,因为这样做不会破坏处理异常的两个原则:
- 处理器不能丢失正确的处理顺序
- 处理器不能错过异常
优先处理高级别异常,会将当前级别的指令所在地址保存在EPC,异常处理完毕后会重新从这条指令继续执行,如果在高级别异常发生的同时还有其他的异常,并且当处理器从异常返回时异常仍然存在,那么在重新执行这串指令的时候处理器有机会处理这些异常。所以为更深的流水线异常赋予更高的优先级是一种正确且高效的做法。
整个流水线控制模块将各个控制信号整合于一个always块中,使用IF语句根据不同层级优先级处理异常。
正如上文所说,MEM级的异常最简单,只有一种类型,而MEM级又是可能发生异常的最深层级,因此其异常优先级最高。在处理异常和中断的always block中处理MEM级异常的IF语句最靠前。然后依次是处理EXE级、ID级和IF级异常的IF语句。最后,外部中断的优先级最低,因此处理他的IF语句在always块的最后。从IF语句的条件可以看到某一层级可能同时出现的异常的类型。具体针对异常的处理我将在后面的小节中详细描述。
1 | always @(*) begin |
异常和中断
当异常和中断发生时,处理器进行的操作有:
- 更新STATUS寄存器关中断
- 更新CAUSE寄存器保存相应的异常号或中断号
- 更新EPC寄存器保存返回地址
- 选择正确的next PC地址
- 生成作用于不同层级的撤销信号
STATUS、CAUSE、EPC寄存器属于CP0寄存器组,他们除了受异常中断的控制外mtc0指令也可以修改他们,因此他们的写入逻辑需要单独处理,异常和中断模块只是生成由于异常和中断引起的相应CP0寄存器的更新信号:
1 | reg update_STATUS_exc; |
并且为相应的CP0寄存器生成一个多路器用于选择异常中断引起的输入或是mtc0指令引起的输入:
1 | reg [31:0] STATUS_exc_in,STATUS_bak_in; |
由于ID级除了可能产生异常外,还能引起流水线的部分暂停,因此ID级的撤销信号需要特殊处理。这部分是CU较为复杂的逻辑之一。RAW冲突和多周期指令均可能和ID级的异常以及其他级的异常同时发生,RAW冲突和多周期指令也可能同时发生。正如上文所说,若不正确处理流水线暂停,会使处理器错过异常,这违反了异常处理的原则,因此必须正确分析它们之间的关系。我为由RAW引起的指令撤销和异常引起的指令撤销设置了独立的撤销信号:
1 | //由异常引起的ID级撤销信号 |
ID级向外输出的撤销信号是两个撤销信号的或:
1 | //We have two ban signal at ID stage to avoid logic loop, ban_ID_RAW and ban_ID_EXC. |
这两个撤销信号有优先级,ban_ID_EXC的优先级高,由异常产生的撤销信号可以撤销RAW和多周期引起的流水线暂停,而由RAW产生的撤销不能消除RAW和多周期引起的流水线暂停。RAW需要暂停并废弃ID级,多周期仅需要暂停ID级,二者同时发生时,需要暂停并废弃ID级。RAW和多周期引起的流水线暂停是必要的,RAW同时产生暂停和废弃信号,因此由RAW产生的废弃信号绝对不能撤销掉流水线暂停信号。而由异常产生的撤销信号则不同,异常直接废弃掉ID级的指令,也废弃了可能产生的RAW和流水线暂停。ban_ID_EXC作用于need_rs,need_rt和ins_done实现上述撤销功能。
1 | wire ins_done = (canceled | ban_ID_EXC) ? 1'b1 : upc == cycle; |
next PC的值由一个多路器控制:
1 | //select the right npc |
在设置流水线控制信号的always块里首先要给这些控制信号设置默认值。默认情况下,流水线内的指令顺序的执行。
1 | //Default values of control signals |
当MEM级有异常发生时,就要上面所说的一些操作。将STATUS寄存器的值保存到STATUS_bak寄存器,并修改STATUS寄存器中最低位,屏蔽中断;将MEM级传来的异常号编码后送入CAUSE寄存器;将当前MEM级指令的地址保存在EPC作为返回地址;选择BASE寄存器作为next PC;将IF、ID、EXE、MEM级所有的指令均废弃。
1 | //processing MEM stage exceptions |
如果MEM级没有异常,才轮到处理EXE级的异常。但是EXE级要比MEM级复杂一些。处理器的设计目标之一是实现自修改代码的同步,自修改代码是由于MEM级的指令对某一内存地址进行修改,而恰好该内存地址是流水线中已加载的某条指令所在的位置引起的特殊情况。考虑到流水线内已加载指令的先后顺序,这种特殊情况只可能在MEM级前的流水线级中发生,因此EXE级可能出现EXE级异常和自修改代码两种情况。EXE级异常信号exc_EXE由EXE级执行单元输入,自修改代码信号EXE_SMC由CU内部对MEM级写入指令的目标地址比对得出。
这二者有可能同时发生,当他们同时发生时如何确定处理器的行为?事实上,无论优先处理哪种情况,都不会产生错误,但不同的处理顺序影响系统的效率。处理SMC需要将当前级以及之前级的所有指令废弃,并将当前地址作为next PC,重新从内存中读取修改后的新值作为指令,同时不需要修改CP0寄存器组;而处理EXC除需要废弃指令外,还需要将next PC设置为BASE,并修改CP0寄存器组。先处理SMC会重新读取并执行该地址内的指令,若新指令不产生异常,则处理SMC后异常消失,无需再做处理;若新指令仍然产生异常则此时SMC已经处理完毕,处理器直接处理对应的异常就好了。优先处理异常也一样,当异常返回时会重新执行产生异常的指令,而由于cache的同步机制,返回时一定会从内存读取新值。因此当EXC和SMC同时发生的时候,无论先处理谁都不会产生错误。怎样处理系统的性能更好呢?经过考虑,我们发现优先处理SMC可以避免处理EXC,而处理一次EXC至少需要两次跳转;而优先处理EXC虽然可以避免处理SMC,而处理一次SMC只需要一次跳转。所以这里的决策是为SMC设置较高的优先级。所以在EXE级,条件为EXE_SMC的IF语句在前。
1 | if (EXE_SMC) begin |
ID级的异常比较特殊,控制它的信号exc_ID并不是从其它级输入的,而是从指令译码的结果产生的。syscall指令和未实现的指令直接在ID级引发异常,并设定预设的异常号:
1 | //system call and unimplemented instruction will cause exception in ID stage. |
由于ID级还可能产生多周期指令和RAW写后读冲突,因此需要额外分析这两者和SMC、EXC之间的关系。幸运的是,由于syscall不需要寄存器,也不是多周期指令,它不会引发多周期指令和写后读冲突,未实现的指令也是这样。因此当ID级异常发生时,不可能由多周期指令和写后读冲突。针对ID级异常的处理方式于EXE级很像,同样是SMC优先于EXC,只不过要将cause修改为ID_cause,将ID级指令的地址保存在EPC,并且只需要废弃ID和IF级的指令:
1 | //processing ID stage exceptions |
IF级就没有那么幸运了。ID级引发的多周期指令和写后读冲突会对IF级的异常处理产生影响,不仅如此IF级还可能产生分支预测失败异常BP_miss.
首先先分析BP_miss/SMC/EXC三者之间的优先级。如果不优先处理分支预测失败,而处理异常,由于当前PC已经被CU确定为是错误的分支,因此处理异常时向EPC中存放的是错误的地址。考虑到异常处理的原则,这样做会丢失正确的处理顺序,因此必须要优先处理BP_miss. SMC和EXC的优先级前面已经讨论过,优先处理SMC会带来更好的性能。因此IF级异常处理的优先级先确定了下来: BP_miss > SMC > EXC.
然后我们分析这三种异常和ID级可能发生的多周期指令、写后读冲突之间的关系:
- 对于BP_miss
BP miss不会与多周期同时发生,因为当前的跳转指令均是单周期指令。但是他会和写后读同时发生,跳转指令中的源寄存器可能是前一条指令的运算结果,如果不正确处理,正确的跳转目标会因为写后读引起的ID IF级暂停被错过。因此这里在is branch信号中加入了&~ban_ID,只有当ID级的跳转指令是有效的,也就是说写后读被数据旁路和流水线暂停解决后,才可能触发BP miss,这样有效的目标就不会因为流水线部分暂停而错过。 - 对于SMC
SMC会与多周期和写后读同时发生,SMC异常因为MEM级的写入请求产生,而多周期和写后读仅会暂停IF和ID级,因此当他们同时发生时,如果不进行特殊的处理IF级就会错过SMC,将受MEM级写入影响的旧指令送入下一级流水线。这里的处理是结合cache中引入的cancel机制。cache中引入cancel机制原本的目的是规避总线无法处理撤销请求的缺陷,但是考虑到SMC信号生成的时机恰好是新的请求写入MEM级的流水线寄存器的时刻,在这个时候CPU是没有Stall的,I cache的请求已经完成,根据cache的撤销机制,可以知道此时req_sent清零,在这个时刻,cache的请求尚未向总线发出,可以直接撤销。因此,撤销机制可以保证在IF和ID级寄存器写入受阻时,仍能撤销当前受到SMC影响的请求,而SMC请求将npc设置成当前pc,PC的值不需要改变,这和IF级暂停并不冲突。之前对于cache同步机制的要求是总线事务至少需要两个周期,这是因为需要一个周期比对总线上的请求是否在cache中,但是现在SMC由CU进行检测,当MEM级存在一个使当前IF级受影响的请求时,可以在下一个时钟上跳直接废弃改指令而与此同时cache内部也将监听到总线的请求在下一个时钟上跳即可进行valid bit清零操作。 - 对于EXC
由于EXC只和当前IF级有关,因此,由于ID级产生的IF和ID级暂停不会修改IF级的内容,EXC也不会因为多周期和RAW被错过。
这些关系分析好后,处理器的行为就确定了。我把相应的处理加在了BP_miss信号的生成和Cache同步机制中,CU中IF级的代码不需要特殊处理,类似于ID和EXE级,区别是BP_miss的优先级高,并且CAUSE、EPC和撤销信号也有相应的变化:
1 | //processing IF stage exceptions |
当上述这些情况都没有发生、且当前ID级指令不是mtc0指令时(即所谓的正常情况),处理器会相应外部中断。当中断响应发生时,处理器的行为于处理异常类似,只不过在EPC中保存被中断的指令(即当前ID级指令)的下一行的地址(即当前PC)。
1 | //processing external interrupt |
流水线的控制逻辑是CU的核心,我花了很长时间才将其中的各种情况理清。
自修改代码和cache同步
各级自修改代码异常在CU内部根据MEM级写请求和地址信号进行判断。
1 | //self modify code has an impact on IF ID and EXE stage. |
设置一个多路器用于为不同的级的SMC异常产生正确的next_PC, SMC_nPC的值在流水线控制逻辑的always块中被修改。
1 | reg [31:0] SMC_nPC; |
跳转和分支预测
分支预测是处理器将要实现的目标之一。CU中仅仅实现与分支预测器的接口,并提供相应的流水线控制机制。CU中关于分支预测的部分独立于分支预测器的实现,因此在本系统内使用不同的分支预测器时不需要修改CU的内容。
关于分支预测的控制逻辑是这样实现的:当IF级总是按照分支预测的结果进行指令预取,当ID级指令是一个有效的跳转指令时,其跳转目标已经计算得到,此时比对跳转目标和当前预取的指令地址即可知道指令预取是否正确。
因此这部分逻辑分为三部分:
- 确定有效的跳转指令
1 | //These signals are used for the branch predictor. |
- 计算正确的跳转结果
1 | //Jump target for J/Jal instruction. Different with the original MIPS 32 instruction. |
- 将计算得到的跳转结果与指令预取的地址(即当前PC)进行比较得出分支预测失败信号。
1 | //If there's a branch, compare the branch target with the current PC, if the two |
除了分支预测信号和有效的跳转指令信号,分支预测器还需要一些其他的信息才能正确维护跳转历史表,比如跳转计算的结果以及跳转的目标是否是可变的目标。因此专门为此生成两个信号:
1 | //do_branch is HIGH if a branch takes place. |
CP0 寄存器组
CP0寄存器组是CU的重要部分,他们既和一些指令交互(mfc0,mtc0, eret)又直接参与处理器的控制。
首先考虑有哪些情况会向CP0写入数据。mtc0指令、异常中断、eret指令三种情况发生时会写入CP0寄存器。CP0寄存器组同其他寄存器组一样需要一个同步的清零信号。
1 | reg [31:0] CP0_Reg[5]; |
CP0寄存器组的命名和编码如下:
- CP0[0]是CAUSE寄存器,用作中断向量。其编码为
| 31 -29 | 28 -27 | 25 -23 | 22 -20 | 19 - 0 |
|---|---|---|---|---|
| IF | ID | EXE | MEM | interrupt |
- CP0[1]是STATUS寄存器,它的最低位用作中断屏蔽位,其他位保留以后使用。
- CP0[2]是BASE寄存器,他存储中断服务程序的入口。
- CP0[3]是EPC寄存器,他存储中断或异常时的返回地址。
- CP0[4]使STATUS的备份,当发生异常或中断时STATUS的值保存在这里,当从中断或异常返回时(eret),在用这个寄存器的值恢复STATUS寄存器。
清零信号由for循环实现。
1 | always @(posedge clk) |
针对寄存器组中的每个寄存器,依照其写入条件和写入的值,产生写入逻辑:
1 | else begin |
可以看到mtc0的指令比异常的优先级低,当异常和mtc0同时发生时,mtc0向某些cp0寄存器中的写入会被忽略。因此mtc0指令在使用时必须要考虑其发生的时机,以免产生无法预测的结果。
mfc0指令是通过对cp0寄存器组的连续读出和ID级数据输出前的多路器实现的:
1 | wire [31:0] CP0_reg_out = CP0_Reg[rd]; |
测试
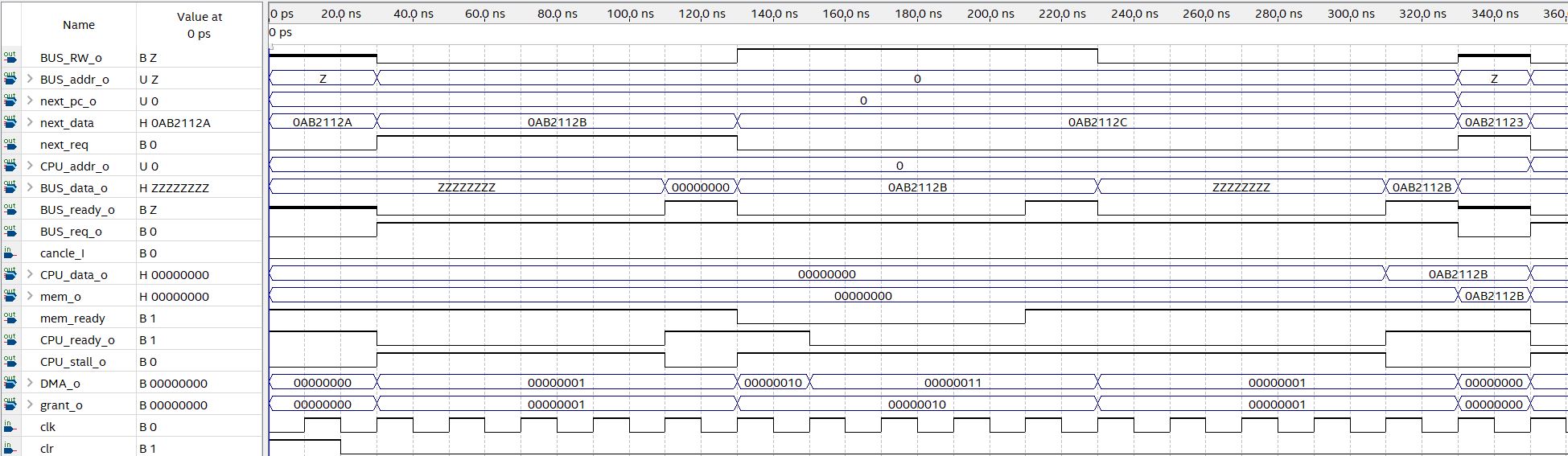
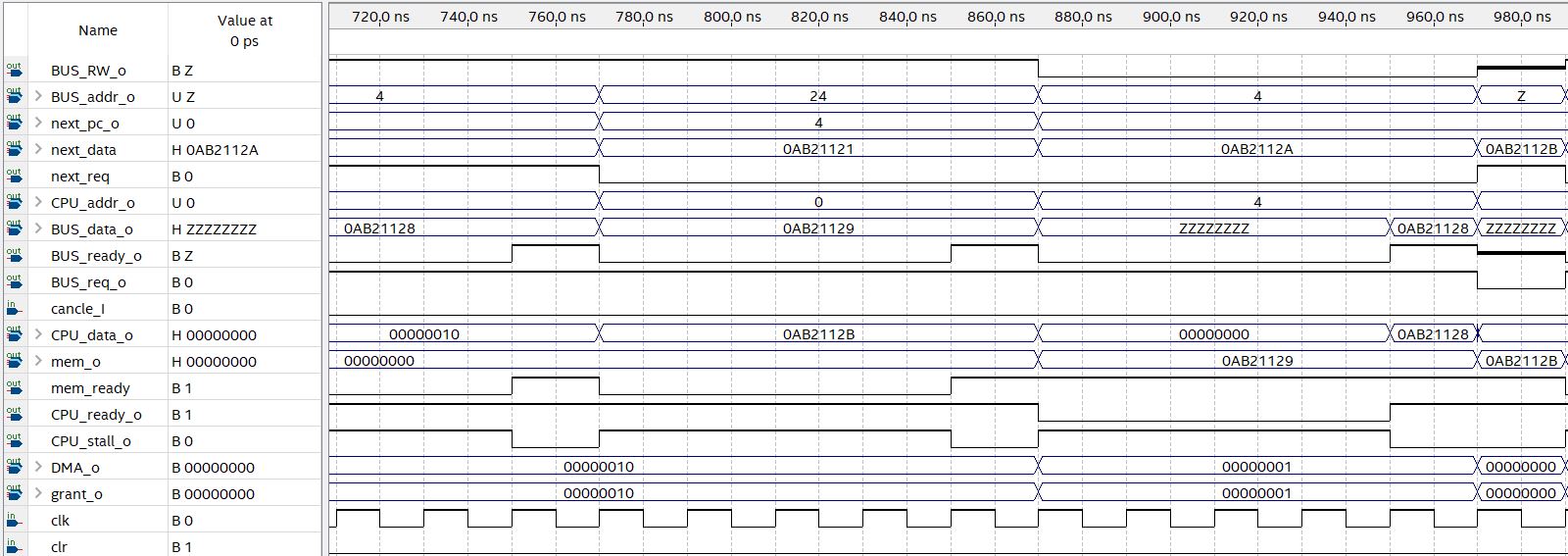
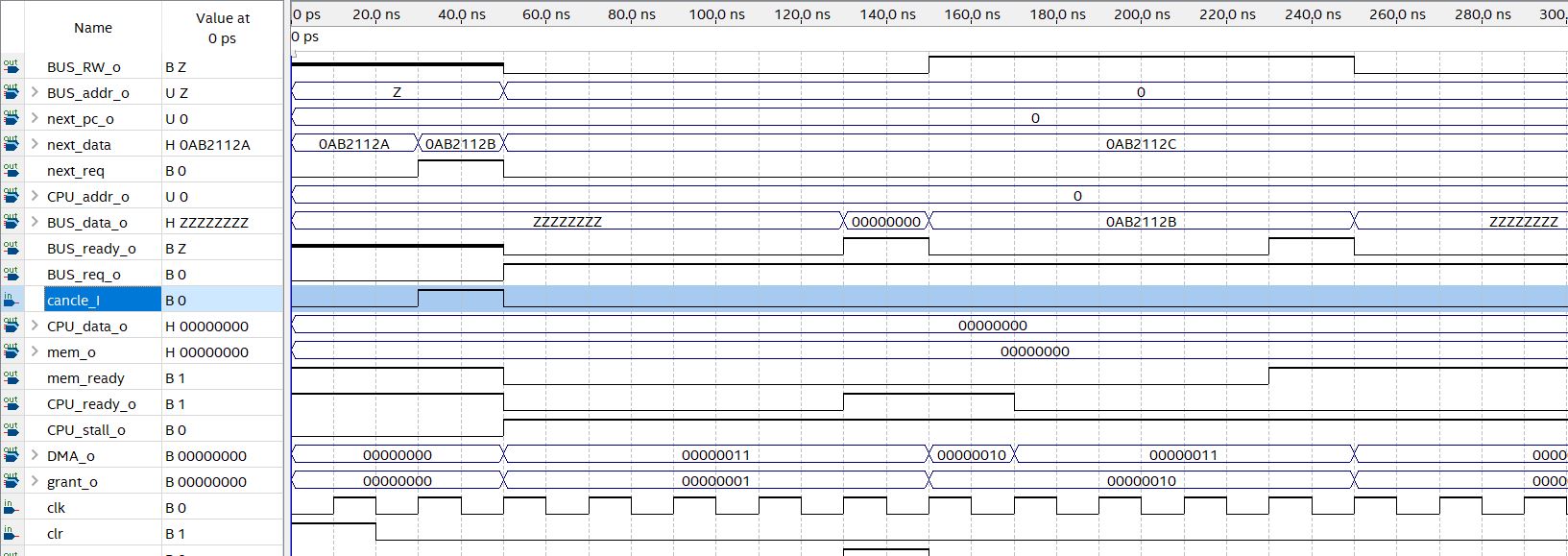
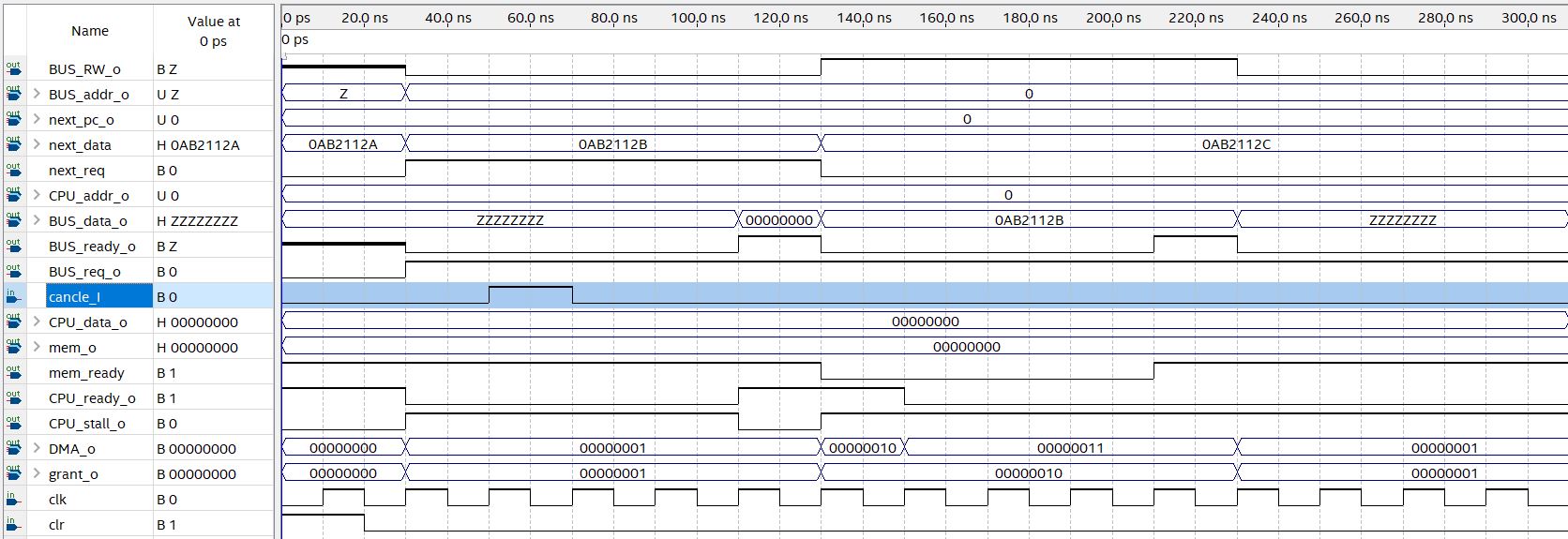
CU需要与处理器内部全部功能部件配合才能发挥作用,因此目前来看测试工作在CPU内部功能部件尚未完全实现前无法进行。我会尽快实现其他级的功能部件,然后编写测试程序,来测试CU的功能是否达成设计目标。
小结
关于流水线的控制逻辑,我确实花了很长时间才想通。这也再次验证了延时槽并不是一个好设计,如果引入延时槽,流水线的控制逻辑会变得更加复杂,是引入超标量流水的巨大障碍。在设计过程中,我也考虑到了未来对超标量流水线的支持。但是路要一步一步走,我需要先把当前的目标实现,积累一套自测试流程和方法,甚至实现工具链的移植,能够方便的在修改设计后验证设计的正确性,在这种情况下才能去实现寄存器重命名等超标量流水线技术。