//internal state machine reg state; always @(posedge clk) begin case (state)
//Idle state, in this state, if has a req, jump to state busy //and register the grant value, this device is chosen, and //other devices' request can't change the output. 0: begin if (req) state <= 1; grant_reg <= grant_inner; end //Busy state, in this state, if has a ready, jump to state idle 1: begin if (ready) state <= 0; end endcase end
//When state == 0 (idle), grant is the instant output of code above //When state == 1 (busy), grant is the registered value. //This lets the grant output stable when one device has already been //chosen. assign grant = state ? grant_reg : grant_inner;
//The req signal will remain untill ready signal is received. assign req = (|grant) ? 1 : 0;
//-------------------------- Module implementation ------------------------- //dummy memory reg [31:0] mem [0:32-1];
//internal state machine reg [ 2:0] state;
//address range reg [31:0] entry_start, entry_end;
//internal registers for bus signal reg [31:0] addr_reg,data_reg; reg r_w_reg,selected_reg;
initial begin entry_start=32'b0; entry_end =32'b11111; state = 0; //ready signal is Z when idle, ready line should have a tri0 //pulldown resistance. because there're other devices on the //bus. ready = 1'b0; addr_reg =0; data_reg=0; r_w_reg=0; selected_reg=0; end
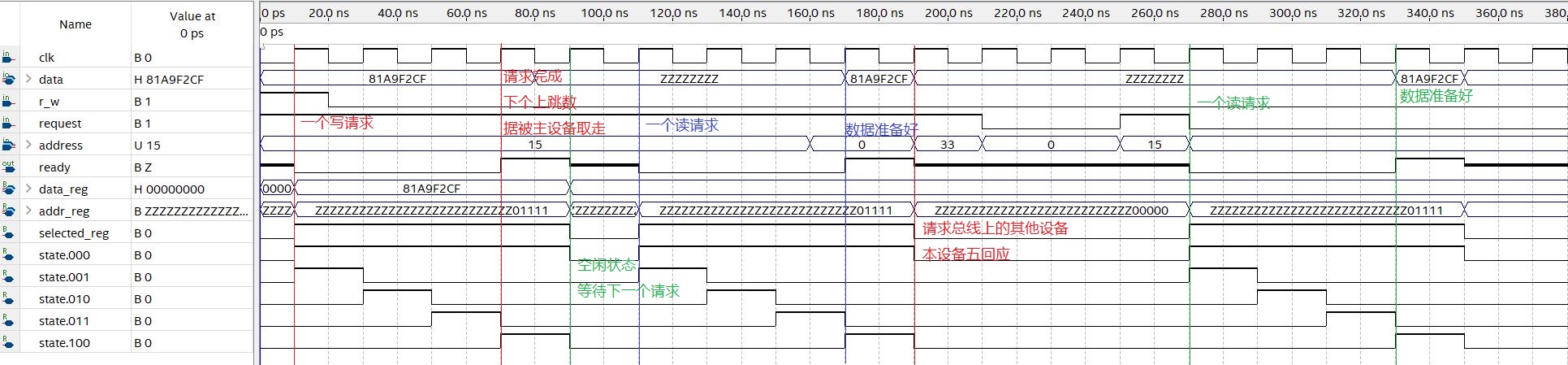
//selected if request in address range reg selected; always @(*) begin if ((address >= entry_start) &(address <=entry_end) &request ) selected = 1; else selected =0;
end //put the ready_out High Z when device is not selected. reg ready; assign ready_out = (selected | selected_reg) ? ready : 1'bz;
//implement inout data port. //if device is selected and the request is a read request, this device //will put data onto the bus. In any other condition, the output will be //high Z. assign data = (selected_reg & ~r_w_reg & ready) ? read :32'bz;
//read is the continuous read data out. wire [31:0] read; assign read = mem[addr_reg];
//the state machine implements the dummy wait cycles and ready signal. //one dummy operation needs four cycles. always @(posedge clk) begin //If device is in idle state and selected, register address, r_w //and data. if ((state == 2'b00)& selected) begin state <= 2'b01;
//pull the ready line low. ready <= 0;
//registered the request addr_reg<= address; r_w_reg <= r_w; selected_reg<=selected; if (r_w) begin data_reg<= data; end end //dummy write and read. elseif (state == 2'b01 ) begin state <= 2'b10; if (r_w_reg) mem[addr_reg] <= data_reg; end //dummy wait. elseif (state == 2'b10) begin state <= 2'b11; end //operation ready elseif (state == 2'b11) begin state <= 3'b100; //one cycle ready signal ready <= 1; end
//goto idle next cycle, ready for next request elseif (state ==3'b100) begin state <= 00; ready <= 1'b0; selected_reg<= 0; r_w_reg <=0; data_reg <=0; addr_reg<=0; end elsebegin //if device is idle, and there's no request on this device //clear all internal registers. state <= 00; ready <= 1'b0; selected_reg<= 0; r_w_reg <=0; data_reg <=0; addr_reg<=0; end end endmodule//dummy_slave
// Declare the RAM variable reg [DATA_WIDTH-1:0] ram[2**ADDR_WIDTH-1:0];
// Variable to hold the registered read address reg [ADDR_WIDTH-1:0] addr_reg;
always @ (posedge clk) begin // Write if (we) ram[addr] <= data;
addr_reg <= addr; end
// Continuous assignment implies read returns NEW data. // This is the natural behavior of the TriMatrix memory // blocks in Single Port mode. assign q = ram[addr_reg];
//dummy memory operation. reg [31:0] mem [0:32-1];
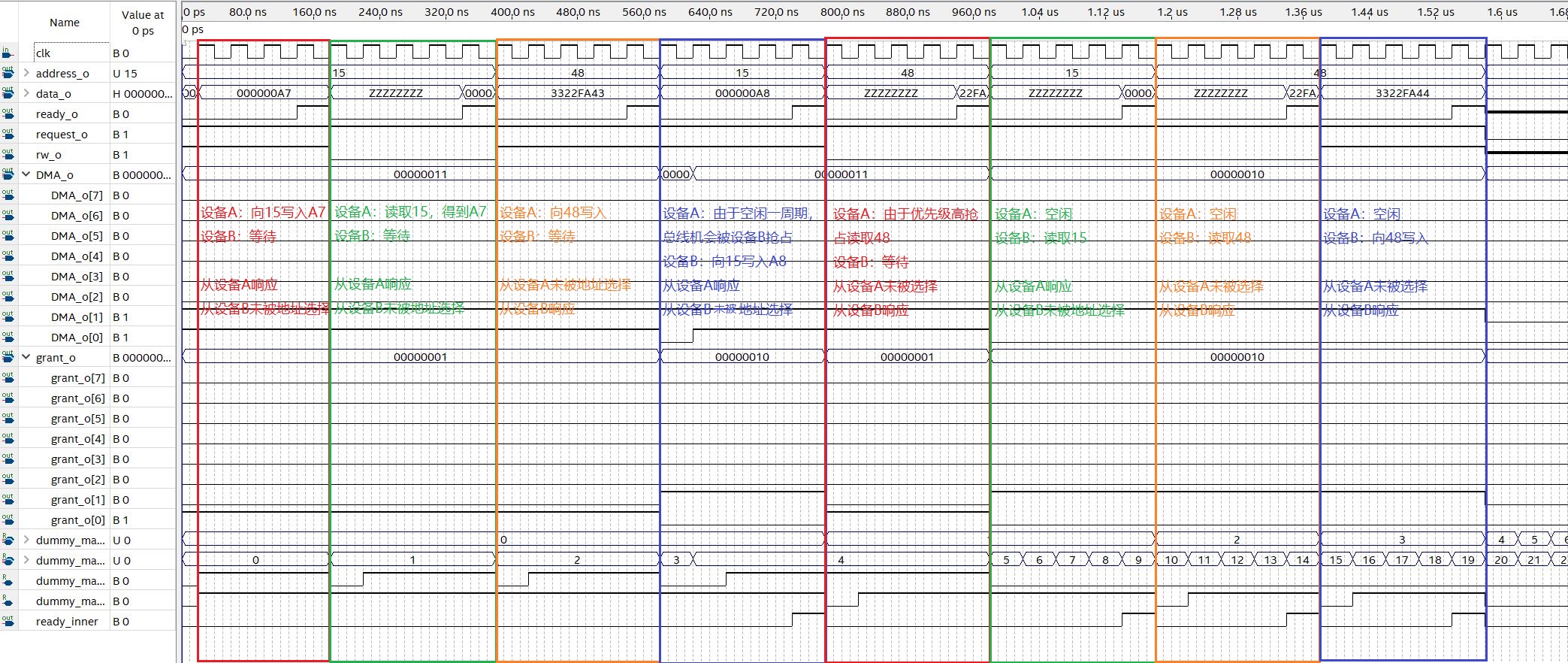
reg [4:0] req_num ; //initial dummy operations. initial begin //simulated operation is here. end //internal state machine. reg state; always @(posedge clk) begin case (state) 1'b0:begin if (request) state <= 1; else req_num<=req_num +1; end 1'b1:begin if (ready_inner) begin if (~req_r_w [req_num]) mem[req_num] <= data; state <=0; req_num<=req_num +1; end end endcase end
assign request = req [req_num];
//High z when not granted assign address = grant ? req_addr[req_num] : 32'bz; assign r_w = grant ? req_r_w [req_num] : 1'bz; wire [31:0] data_out = req_r_w [req_num] ? mem [req_num] :32'bz; assign data = grant ? data_out: 32'bz;
//mask out ready signal when not granted assign ready_inner = grant? ready :1'b0;
//This module is the test bench for bus module bus_t( clk,address_o,data_o,request_o,ready_o,rw_o,DMA_o,grant_o ,ready_inner ); output [31:0] address_o, data_o; output request_o, ready_o,rw_o,ready_inner; output [7:0] DMA_o, grant_o;
input clk;
//These wires are internal bus signal wire [31:0] address,data; wire request, ready, r_w; wire [7:0] DMA, grant;
//these ports are used by the simulator output assign address_o =address; assign data_o = data; assign request_o = request; assign ready_o = ready; assign rw_o = r_w; assign DMA_o = DMA; assign grant_o = grant;