我在上一篇文章中,描述了我在设计cache过程中遇到的困难以及产生的想法,提到了fpga片上的RAM隐含的寄存器引起的设计困难,cache同步的问题以及本平台目前对cache同步机制的目标。经过半个月的设计与测试,本系统中将要使用的两路组相联cache(2-way set associative cache)设计完毕并通过测试。这篇文章主要介绍我的设计实现和测试过程,可以作为我所写的代码的文档使用。
cache 设计目标
- 只需一个时钟周期即可计算出是否cache命中,命中后立刻通知CPU
- 2路组相联设计
- cache写策略为写透(每当有写请求,同时写入cache和内存)
- cache替换策略为随机替换
- 允许通过改写参数自定义无需缓存的地址空间供IO和DMA设备使用
- 允许通过改写参数改变cache的规模
- 指令和数据cache都是本模块的实例
- 多个cache实例可以同时访问系统总线
组相联cache的设计与实现
组相联cache并不是高大上的技术,在许多参考书中都有介绍,并且在现代处理器中大量使用。但是互联网上有关组相联cache设计与实现的文章并不多,更多的是对其理论概念的描述。看起来组相联cache是很简单的,但这样一个简单的模块,实现起来也需要下点功夫。
关于组相联cache的理论,在这篇文章里我就不赘述了,直接切入正题。
在本平台中使用的cache原理图如下,图中的信号名称和代码中的信号名称一一对应。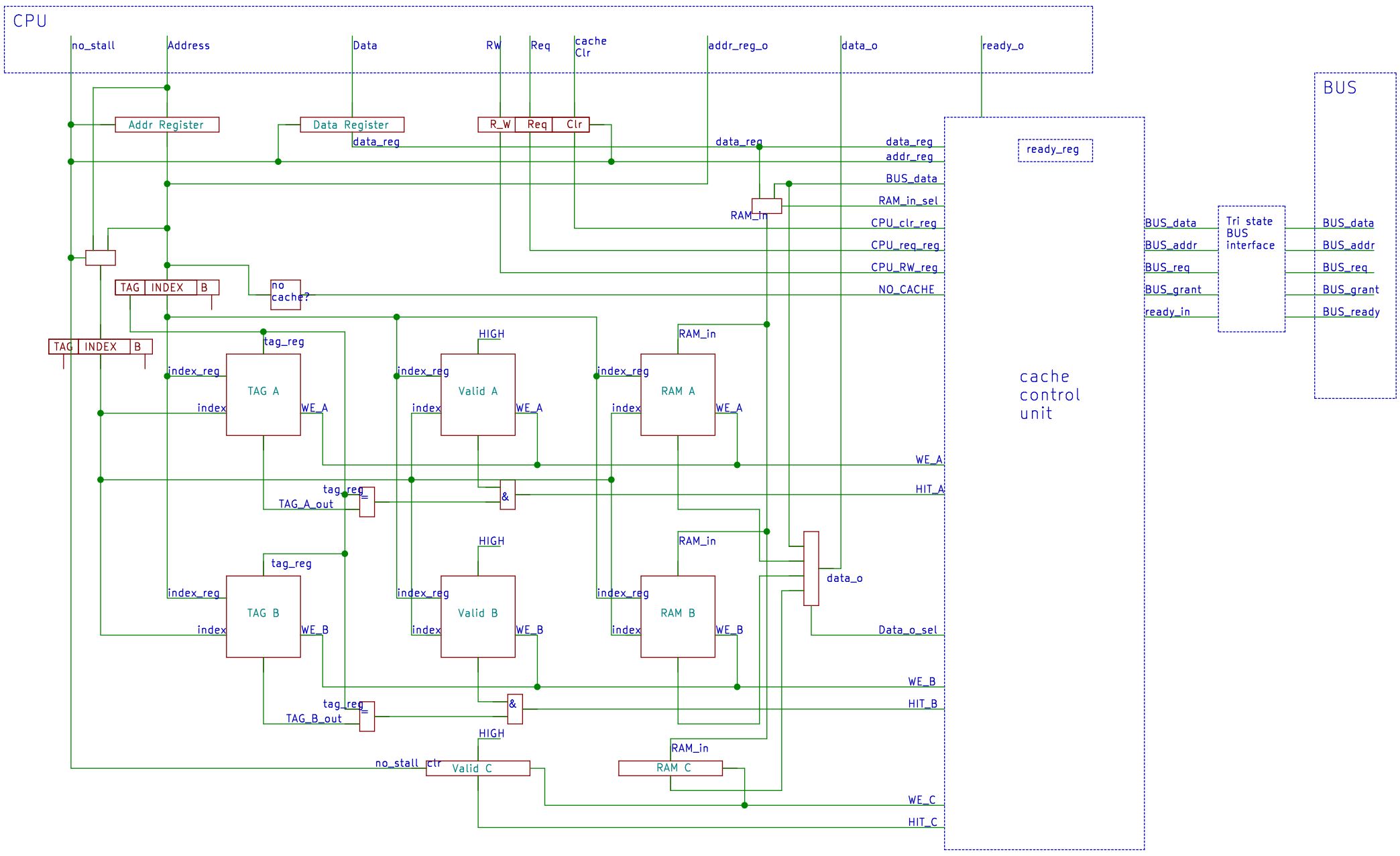
整个cache主要分为四部分,分别是与CPU和总线的接口、内部的存储器组以及控制单元。在这个平台上,指令cache要比数据cache简单,因为指令cache是只读的,因此如果为指令cache和数据cache涉及两个不同的模块会减少对FPGA资源的占用。但是我偷了个小懒,让两个cache共用一个模块,这样大大减少了我的工作量。
与CPU的接口
如图中所示,cache与cpu的接口包括:
- CPU_stall 信号,该信号是由CPU ID级的CU根据两个cache的状态产生的反馈。
- CPU_Addr 总线对于指令cache来说,应该直接与NextPC多路器的输出相连,对于数据cache则与EXE级的地址计算结果直接相连。直接与前一级输出而不是与流水线寄存器相连,是为了在使用板载RAM的基础上仍能满足一个周期得到cache命中结果的关键。板载RAM上有内置的寄存器,如果地址输入不与前级输出直接相连,需要至少两个周期才可以知道cache命中的结果,数据要先经过流水线寄存器,再经过板载RAM内部地址寄存器,才能输入结果。
- CPU_data 总线对于指令Cache来说应当全部是零,因为指令cache是只读的;对于数据cache应直接连接前一级的输出。
- CPU_req 信号,高电平表示需要从cache获取数据或指令。对于I cache而言,该信号应始终是高电平,因为CPU总是需要获取新的地址;而对于D cache,该信号应与前一级输出相连,由CPU的ID级给出的信号控制,因为不是每条指令都需要访问D cache。
- CPU_RW 信号标志当前请求是读请求还是写请求。该信号对于I cache而言始终是低电平,因为其是只读的。对于D cache 应直接与前一级输出相连,由ID级控制。
- CPU_clr 信号是控制cache内部的valid bits的清零信号,如果该信号为高电平,则下一时钟上跳时清除整个cache的valid bits。我会在ID级实现两个分别清零I cache 和D cache的指令,用这个指令提供软件控制的缓存同步机制。当存在自修改代码时,系统程序员应使用相应的cache清零指令。
- data_o 是向CPU输出的准备好的数据。
- ready_o 信号表示cache是否准备好。
在这里值得说明的是,由于FPGA板载ram上有内置的register,地址输入必须直接与上一级相连,这在某种程度上会引起流水线寄存器设计的割裂。因此,我将所有上一级来的输入信号全部设计成与cache模块直接相连,在模块内部并行的增设寄存器,将与cache相关的流水线寄存器放置在cache内部,并设置了这些寄存器的输出接口如addr_reg_o,供下一级流水线使用。
与总线的接口
在总线控制器的设计时我使用了三态门,但是实际综合出的逻辑不能识别高阻态,因此在设计时要考虑对高阻态信号的屏蔽。总线接口包含:
- BUS_addr 地址总线
- BUS_data 数据总线
- BUS_RW 读写标志
- BUS_req 总线请求标志,该信号应连接总线控制器上的DMA[0:7],根据DMA编号不同实现不同的优先级。
- BUS_grant 总线请求许可,该信号从总线控制器发来,当总线请求获得控制器的许可后该信号为高电平,该信号主要参与总线接口三态门的控制。
- BUS_ready 信号,高电平标志总线请求结束。
系统总线接口这部分的代码主要是对总线上三态门的控制,逻辑设计要保证总线上其他设备的信号不能干扰本设备。
首先要保证当且仅当总线请求被控制器允许后才能向总线发送数据:
1 | //BUS Interface |
同时也要确保只收到发送给自己的ready信号,在自己没有总线请求时过滤掉总线的ready信号,保证ready信号线上的高阻态不会影响自己。
1 | wire ready_in = BUS_grant ? BUS_ready : 1'b0; |
总线的数据接口是双向接口,向总线发送写请求时,直接将数据送至数据总线;发起读请求时,应设置为高阻态,直接从数据总线读取数据。
1 | wire [31:0] data_to_bus = CPU_RW_reg ? data_reg : 32'bz; |
在读cache不命中、写入或读写不需要cache的地址时,才应像总线发起请求,其他情况让出总线的控制权。
1 | assign BUS_req = CPU_req_reg && ((~CPU_RW_reg && ~CACHE_HIT_R ) |
值得说明的一点是,由于模块的输入都是上一级的直接输入,寄存器在模块的内部,而且cache的ready信号与cpu的stall信号直接有关,因此控制信号的逻辑需要小心设计,避免出现组合逻辑环。也就是说cache的ready信号应该只和模块内的寄存器的值有关系,不应当与stall信号直接相关。可以看到总线接口的设计遵循了这样的原则。当总线ready时,cache应同时给cpu ready信号,因此cache的ready信号与总线的状态有关,总线的状态也应该仅与寄存器中的值相关。在总线接口部分,所有的控制信号均使用寄存器中的值而不是上一级的直接输入。
cache内部的存储器
如图所示,cache内部共有三类存储器,分别存储TAG、有效位(valid bits)和实际请求的数据(RAM)。
这个cache模块可以通过改写参数的方式改变cache的规模,cache的规模由索引的宽度INDEX表示,INDEX默认值是7,也就是说内存地址出去字内地址低两位,[INDEX+1:2]这个范围作为七位的索引,因此可索引cache_lines = 2<< (INDEX -1) 行,在TAG中存储的TAG尺寸为tag_size = 32-2- INDEX。
1 | //Number of Lines in each group. |
所谓2路组相联,意思是每个index可以索引两组内容,分别存放在A、B两组TAG、valid bits和RAM中,同时对比两组的TAG和Valid bits,得到cache命中结果。对比直接镜像的好处是自由度更大一些,当读取到两个index相同的内存地址时,这两个数据都可以存放在cache中,而在直接镜像的情况下,此时就会发生cache替换。
首先定义index和tag:
1 | //vector index is for indexing the whole cache. |
然后定义TAG、Valid bits和RAM三个存储器。以其中A组为例代码如下:
1 | //Memory for TAG_A. |
这里有一些细节值得说明。index信号是对addr的截取,addr根据当前cpu的状态选择直接从上一级流水输入的地址或是内部寄存的地址。index_reg是从内部的地址寄存器截取的。同时使用两个信号是实现单个周期计算是否cache命中的关键。在上述的三个存储器中,可以看到所有的读接口的索引都使用index,这就保证了在第一个时钟周期上跳,存储器就已经将新读取结果。而对这些存储的修改仅当cache不命中或者写透时才发生,因此写入最早应该发生在下一周期上边沿(因为总线上的设备的响应时间不同,如果总线上的设备能够在当前周期内相应,就是所谓的最早的情况),而这个时候上一级流水输出的信号已经发生改变了,我们并不能阻止这种改变发生,因此所有的写入信号都应该使用内部寄存器的输出(这个内部寄存器就是流水线寄存器)。这里我们使用stall信号来区分cpu的状态,如果此时stall信号为低电平,这说明cpu在处理新指令,index的值是直接从上一级截取的,使用index提供的索引读取cache内部存储判断是否命中,若不命中,则等待总线响应,同时通过ready信号使cpu暂停,此时stall信号为高电平,此后的周期直到缓存准备好,读请求的索引index都被stall信号选择成内部的寄存器输出,可确保在上一请求没完成时继续读取上一索引。
这里使用了阻塞赋值语句,对于同时写入和读取同一个地址的情况,读取的结果是写入的新值,综合的结果会加入一些数据旁路来符合我们定义的行为。总是读取新值在我的设计中是必要的,因为当总线准备好时,当前cache也准备好,而此时另一个cache可能尚未准备好正在请求总线,因此cpu要继续等待。此时下一个时钟上边沿,当前cache将新的TAG、Valid bit和RAM写入cache,但是总线上的ready信号随即消失,我们需要在这个时钟上边沿直接取得cache命中信号,让cpu等待时不错过这次请求的cache信号。总是读取新值可以保证在总线准备好后的下一个时钟上边沿就能输出cache命中信号。
对于valid bits,由于存在着清零信号,由于altera的板载存储不支持清零信号,所以它会被综合成寄存器。而其他两块存储会被综合成存储器,使用片上的RAM资源。我所设想的设计目标是不用商业IP,与FPGA无关,使用标准的硬件描述语言设计,在没有片上RAM资源的FPGA上这段代码仍然能够综合,不过要消耗大量的寄存器资源。
valid bits的读出应该是寄存器而不是assign连续赋值,因为valid bit的输出直接关系到ready信号,而index与stall信号有关,如果使用连续赋值,会产生组合逻辑循环。
针对不需cache的地址范围的特殊设计
我所设计的CPU采用memory mapped IO设计,IO使用访存指令来控制。在不提供额外的硬件缓存同步机制的情况下,IO所使用的地址范围会产生cache同步问题。我采取MIPS的做法,在不需要cache的内存空间中绕过cache。
具体做法并不复杂。
首先使用一个寄存器NO_CACHE判断当前请求的地址是否在不需要cache的范围,该寄存器仅在获取新请求时更新。
1 | reg NO_CACHE; |
然后引入组C作为作为这no cache区域的缓存。设计这组缓存是必要的,原因上面已经介绍了。因为每次对这一地址范围的请求都是cache不命中,都需要从总线上获取数据。总线上的数据仅仅存在一个周期即总线ready的那个周期。如果CPU在这个周期由于其他的原因stall,CPU就会错过总线上的数据,因此我们在这引入额外的一组C,C组没有TAG,valid bits只有一位,RAM也只有一行,在总线ready后,同其他组一样,将总线来的数据写入到RAM同时更新valid bits,为CPU提供cache命中信号。
除此之外,绕过cache的机制也很简单,直接在每次新请求发生时,将C组的valid bit清零即可实现每次对no cache区域的访问都不命中。
1 | reg VALID_C; |
引入C组的好处是在提供目标功能的同时,简化了控制单元的设计,控制单元只需要根据NO_CACHE寄存器的结果选择相应的信号即可。
各组的更新信号
WE_A, WE_B, WE_C为三个组的更新信号。该信号由cache控制器计算,每次更新只有其中一个有效。
cache控制器的设计与实现
cache控制器主要解决三方面的问题:
- 命中信号的逻辑
- 不命中时的cache替换
- 写入cache的内容和向CPU输出的内容的选择
cache命中信号ready_o
上文中我已提到,BUS上的数据只存在一个周期,但是CPU可能在这个周期因为其他原因暂停。因此我们必须在总线就绪时将数据保存在cache内部。这样的操作自然应该包含BUS的ready信号。
引入一个寄存器ready_reg保存从总线上接收的就绪信号, 该寄存器在新请求到来时清零。
1 | reg ready_reg; |
针对三个组,每个组都要有单独的命中信号。
1 | wire HIT_A = tag_reg == TAG_A_out && VALID_A_out; |
可以看到在AB两组的命中信号比对过程中,使用的全部是经过寄存器同步的值,这避免了从cpu_stall到ready_o之间的组合逻辑环。
有了各组的命中信号后,就可以为读请求设置命中信号。若请求在no cache范围,则以HIT_C为准,否则与AB的或为准。
1 | wire CACHE_HIT_R = NO_CACHE ? HIT_C : (HIT_A || HIT_B); |
最终的命中信号ready_o还与一些其他的信号相关:
- 如果此时并没有请求cache(cpu_req_reg == 0),则应直接给出命中信号,通知CPU继续工作。
- 如果是写请求,则命中信号应是总线就绪信号与ready_reg的逻辑或。
- 如果是读请求,则命中信号应是总线就绪信号与读命中信号(CACHE_HIT_R)的逻辑或。总线就绪信号使用请求信号进行过滤,防止高阻态的ready干扰。
1
2
3
4
5
6
7
8
9always @(*)
begin
if (~CPU_req_reg)
ready_o <= 1;
else if (CPU_RW_reg)
ready_o <= (CPU_req_reg && ready_in) || ready_reg;
else
ready_o <= (CPU_req_reg && ready_in) || CACHE_HIT_R;
end
cache替换控制
当读不命中或有写请求时,要进行cache的更新。Cache的更新机制主要解决两个问题:
- 何时更新?
- 更新那一组?
第一个问题非常简单,当且仅当总线上数据准备好的时候更新cache,因为所有的不命中都需要请求总线。
1 | wire need_update = BUS_grant && ready_in; |
第二个问题稍微复杂一些。我们使用随机替换策略,首先要设计一个简单的随机数产生器。这里我使用一个计数器作为随机数产生器。
1 | reg random; |
对于不需要cache的地址范围,处理比较简单。因为组C只有一行,因此直接替换即可。
1 | assign WE_C = NO_CACHE && need_update; |
对于正常的情况,处理稍微麻烦一些,并不是很多读者想象的直接利用上面描述的随机数产生器。
考虑这样的几种情况:
- 如果一行内的两组槽位,有一个是空的应该,可以直接往空的组填写数据吗?
很遗憾答案是否定的。 - 如果两组都是满的,可以直接使用随机替换吗?
很遗憾答案还是否定的。
为什么不能直接使用随即替换呢?这里有一种特殊情况:
如果两组都是满的,A内存放地址0的缓存,B内存放地址8的缓存。此时我需要向地址0再次写入新值。这种情况下能使用随机替换吗?答案当然是否定的。我们应该优先替换TAG相同的组。这种情况下应当将对地址0写入的新值直接放入原来就存放地址0的组A,而不是随机替换组B。这样做除了有性能优势以外,还保证了cache不发生意外地错误。如果直接使用随即替换替换掉了B组,则cache内会有两条关于地址0的记录,在没有额外的措施的情况下,这就直接引起了错误!CPU不知道那个数据是正确的。
因此我们确定了使用随机替换时的策略:
- 若cache内已经存放有该地址的记录,直接替换这一组,不使用随机替换。
- 否则再看是否有空闲的组,如有则放入空闲组,否则使用随即替换。
信号WE_A,WE_B实现了上述逻辑:需要留意的是,这里使用的控制信号也都是经过寄存器同步过的,这样可以避免组合逻辑环。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18reg [1:0] group_sel;
always @(*)
begin
//replace group with the same tag first.
if (TAG_A_out == tag_reg)
group_sel <= 2'b01;
else if (TAG_B_out ==tag_reg)
group_sel <= 2'b10;
//if both group is empty or valid, randomly choose one group.
else if (VALID_A_out == VALID_B_out)
group_sel <= random ? 2'b01 : 2'b10;
//if only one group is empty, choose the empty group.
else
group_sel <= VALID_A_out ? 2'b10 : 2'b01;
end
//only when requested address is in cache range, WE_A or WE_B can be active.
assign WE_A = (~NO_CACHE) && need_update && group_sel[0];
assign WE_B = (~NO_CACHE) && need_update && group_sel[1];
向cache内写入的数据和对CPU输出的数据选择
我们需要根据读、写请求的不同以及总线的状态,选择向cache内写入的数据RAM_in和向CPU输出的信号data_o.
对于RAM_in。读请求时,应选择总线上的数据BUS_data;写请求时应选择CPU从上一级流水线输入的数据data_reg.
1 | assign RAM_in = CPU_RW_reg ? data_reg : BUS_data; |
对于data_o。若是写请求,则不需要向cpu输出数据;若是读请求,当总线准备就绪时,总是选择总线上的数据,若错过了总线的就绪信号,则按照各组的命中情况,选择各组的RAM作为输出。其实现代码如下:
1 | always@(*) |
至此这个符合上文所述的设计目标的cache模块设计完毕了。接下来是繁琐的测试工作。
组相联cache的仿真、测试
从这篇文章的篇幅来看,这绝不是一个简单的系统,因此其测试也需要仔细考量。本文开头所描述的设计目标应当全部包含在测试中。经过我的思考,确定了测试的流程:对于功能测试,均采用单个cache实例;在通过了功能测试后,使用多个cache实例测试其联合访问总线。这样做是合理的,确保单个cache功能正常,多个cache联合访存正常即可说明达到了设计目标。
针对单个cache的功能测试
首先准备测试代码。
先定义总线信号:
1 | wire [31:0] BUS_addr, BUS_data; |
然后实例化单个cache和模拟的内存控制器,实例化总线控制器,并将他们连接到总线上。
1 | //hook up the bus controller |
可以注意到这个cache实例是连接在DMA[0]上的,因此他具有最高的总线优先级。
设置模拟的CPU_stall信号:
1 | wire CPU_stall = clr ? 0: ~(CPU_ready && 1); |
然后就可以使用不同的预设请求序列来测试cache的功能。
初步测试
测试了cache的基本功能:
- 读不命中、读命中
- 写不命中,连续写不命中,写后读命中
- 读写no cache范围
使用如下的测试序列1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38reg [31:0] address [0:7] ;
initial
begin
address[0]= 0 ;
address[1]= 4 ;
address[2]= 0 ; //cache hit
address[3]= 16 ;//write
address[4]= 16 ;//read
address[5]= 8 ; //read in no cache zone
address[6]= 8 ; //write in no cache zone
address[7]= 8 ; //read in no cache zone
end
reg [31:0] data [0:7];
initial
begin
data[0]= 32'hab2112a ;
data[1]= 32'hab2112b ;
data[2]= 32'hab2112c ;
data[3]= 32'hab21123 ;
data[4]= 32'hab21124 ;
data[5]= 32'hab21128 ;
data[6]= 32'hab21129 ;
data[7]= 32'hab21121 ;
end
reg [7:0] rw;
initial
begin
rw[0]= 0 ;
rw[1]= 0 ;
rw[2]= 0 ;
rw[3]= 1 ;
rw[4]= 0 ;
rw[5]= 0 ;
rw[6]= 1 ;
rw[7]= 0 ;
end
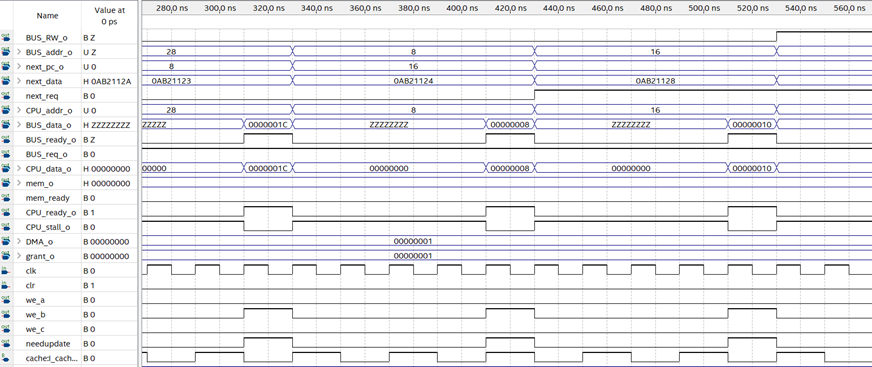
测试结果如图: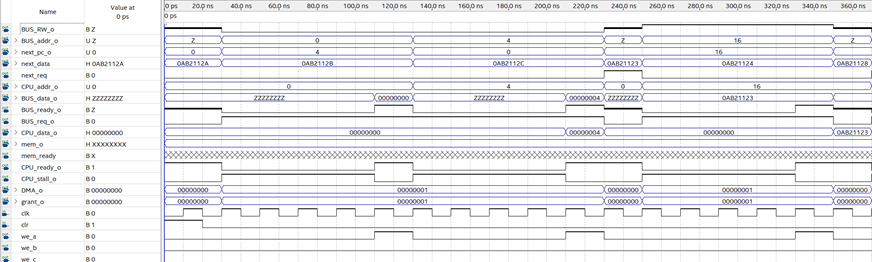
从图中可见:
读取0,110ns数据准备完毕,130ns进入下个请求,此次请求未命中。
读取4,210ns数据准备完毕,230ns进入下个请求,此次请求未命中。
读取0,此次请求命中,数据在一周期内准备完毕,总线空闲,250ns进入下个请求。
写入16,写请求总是未命中,330ns写入完毕,350ns进入下一个请求。
读取16,写后读命中,数据在一周期内准备完毕,总线空闲,370ns进入下个请求。
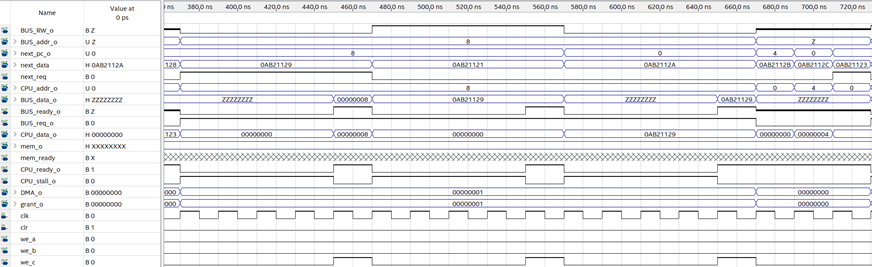
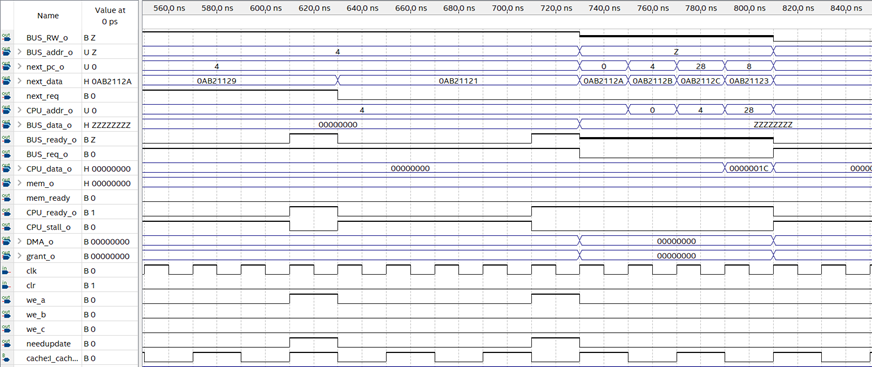
从图中可见:
读取8,请求no cache范围,总是不命中,450ns数据准备好,470ns进入下个请求。
写入8,请求no cache范围,总是不命中,550ns数据准备好,570ns进入下个请求。
读取8,请求no cache范围,总是不命中,650ns数据准备好,670ns进入下个请求。
这一段测试了有限的缓存同步机制。
后续三个请求读取0,4,0均命中。
基础功能测试完毕。
替换策略测试
替换策略的测试稍微繁琐一些。经过思考我决定先将cache的规模缩小,缩小到最小。当cache规模缩到很小的时候,就很容易制造cache替换的模拟,然后进行测试。
将参数INDEX改为1,此时cache的规模为两组,每组两行。然后执行序列:
1 | reg [31:0] address [0:7] ; |
仿真结果如图: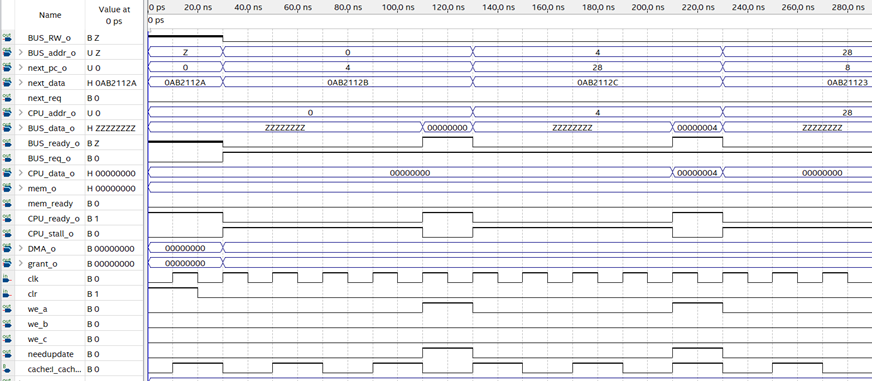
分析上述序列的过程:
| 时刻 | 120ns | 220ns | 320ns | 420ns | 520ns | 620ns | 720ns |
|---|---|---|---|---|---|---|---|
| 请求 | 0 | 4 | 28 | 8 | 16 | 4 | 4 |
| TAG | 0 | 0 | 11 | 1 | 10 | 0 | 0 |
| INDEX | 0 | 1 | 1 | 0 | 0 | 0 | 0 |
| 行/组 | 0A | 1A | 1B | 0B | 0B | 1A | 1A |
| 策略 | TAG相同组 | TAG相同组 | 空的组 | 空的组 | 满,随机 | 满,随机 | TAG相同组 |
由仿真结果可知,替换策略通过测试。
多个cache的联合访存测试
单个cache的功能测试完,达到设计目标后,就要测试多个cache联合访问总线的测试。这个测试不单测试cache功能,还要测试总线的功能。
首先将两个cache实例分别作为I cache 和D cache连接在总线和总线控制器上:
1 | //hook up the simulated instruction cache |
D_cache接在DMA[1]上,表明指令cache的优先级比数据cache的优先级要高。
然后设置合适的CPU_stall信号:
1 | wire CPU_stall = clr ? 0: ~(CPU_ready && mem_ready); |
最后加载模拟的测试请求:
1 | //for I cache |
仿真结果如图: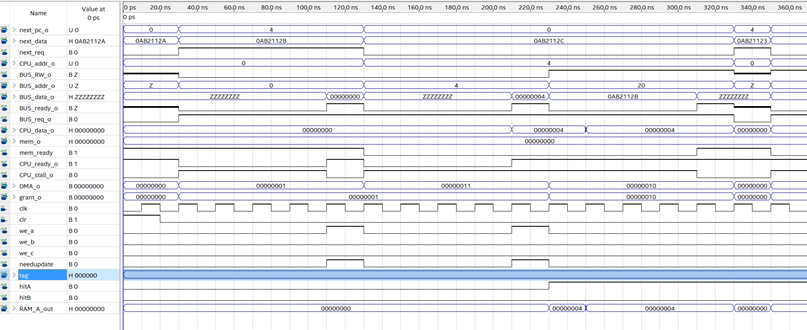
0-130ns:
I cache未命中访问总线,D cache无请求,130nsCPU准备好接收下一个请求。
130ns-330ns:
I cache未命中优先访问总线,230ns访问完成轮到D cache访问总线,330ns CPU准备好接收下一个请求。
330ns-350ns:
I cache和Dcache均命中,总线空闲,350ns CPU准备好接收下一个请求。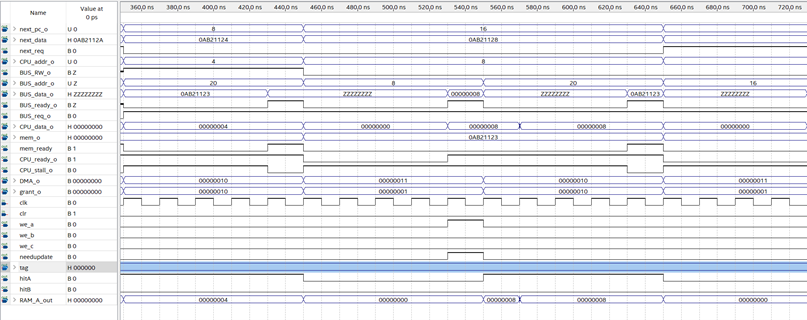
350ns-450ns:
I cache未命中 访问总线,D cache命中,450ns CPU准备好接收下一个请求。
450ns-650ns:
I cache未命中优先访问总线,550ns访问完成轮到D cache访问总线,650ns CPU准备好接收下一个请求。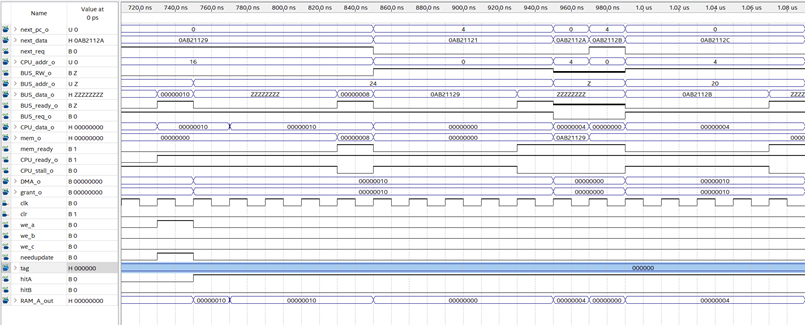
650ns-850ns:
I cache未命中优先访问总线,750ns访问完成轮到D cache访问总线,850ns CPU准备好接收下一个请求。
850ns-950ns:
I cache命中, D cache未命中,访问总线,950ns访问完成,CPU准备好。
950ns-970ns:
I cache、D cache均命中,CPU在一个周期内准备好。
970ns-990ns:
I cache、D cache均命中,CPU在一个周期内准备好。
由仿真结果可知,两个cache可以按照优先级共同访问系统总线,而且cache的存在对CPU的性能提升很有帮助。我们总线上挂的模拟内存控制器需要5个周期100ns事件才能将数据准备好。30-990ns的时间内,共48个时钟周期,共完成了9条指令。若cache不存在,每条指令需要10个周期才能完成,最多才能执行4.8条。
已知问题
我的总线设备和总线控制器不知道如何解决对设备中没有的地址的访问。
如果访问的地址不在设备的范围内,系统就会出现异常。
目前的解决方案:无,程序不应访问不在设备范围内的地址。
小结
我在实现过程中遇到的最大的问题莫过于组合逻辑环。因为FPGA片上存储的特性(隐含的寄存器),我必须在模块的某些输入上直接绕过流水线寄存器,并依据CPU_stall进行选择,这就非常容易引入从CPU_stall信号到ready_o信号之间的逻辑环。我在这个问题上花了很长时间进行调试,最后总结出,只在片上RAM的地址输入上使用这个由stall信号选择的输入,其余的控制电路均要使用经过寄存器同步的输入。因为片上ram读取结果是由寄存器同步的,因此这样绕过流水线寄存器不会引起组合逻辑环。
组相联cache在各种教科书中都有提及,但其篇幅往往不长,往往并不能描述其具体实现。我做这件事,写这些文章,一是满足自己的欲望,二是希望能够通过动手实践来填补理论和实践之间巨大的鸿沟,这篇文章的篇幅就很能说明问题。
组相联cache设计完之后,我的欲望再一次膨胀了。是否加入分支预测,撤掉有些过时的延时槽?是否可能实现简单的超标量流水线?这些还是等到整体设计完再说吧。