上篇文章详细描述了组相联cache的实现和测试,文中小结也提到了测试成功后笔者有点小膨胀,想实现更多的功能。本系统内使用的cache和总线已经完成测试一个多月,这一个多月里,我主要思考的是流水线的控制问题。而且我确实膨胀了,我准备修改我的设计目标,实现分支预测和硬件cache同步。这样的设计目标无疑使得流水线的控制变得复杂。因此我在这一个月的时间里,详细列举了在引入分支预测、cache同步、异常和中断以及多周期指令和写后读冲突后的流水线控制问题,一边思考这个问题,一边初步搞定了cache同步机制的设计。
这篇文章主要描述Cache同步机制的设计。
为什么要引入cache同步机制?
很多人认为在我这样一个单核心单线程的处理器内部是不需要引入cache同步机制的,实际上这种说法是错误的。我在上一篇文章中已经描述了在这样一个处理器引入同步机制的原因主要是Memory Mapped IO 和自修改代码(self-modified Code)。对于Memory Mapped IO 上一篇文章中所提出的组相联Cache的设计,已经使用了一段可自定义的地址空间来绕过Cache,将这段地址空间用于IO即可满足IO的cache同步问题。而对于自修改代码,之前的设计是准备引入一些控制cache同步和清零的指令,将cache同步的任务交给系统程序员。显然,这种处理方法只是权宜之计。普遍认为,将系统的微架构过多的暴露给程序员是一种很糟糕的选择,我自然倾向于像X86一样设计一套对同步的硬件。
本平台中的自修改代码会在两种情况发生:
- DMA
- MEM级的store指令
DMA设备绕过处理器直接通过系统总线修改内存,如果修改的地址正好在cache的缓存中,这就会引起cache的同步问题。发生在MEM级的store X 指令也是如此,程序员编写的程序有可能通过store指令修改代码段内的数据,这会引起cache的同步问题。
发生cache同步事件时各事件的顺序
要想弄清楚cache的同步过程,首先要明确各种事件谁先谁后的问题。这个问题十分关键,它决定处理器在cache同步发生时的行为。
首先明确两种顺序:一是程序员所写的代码的顺序,我将这种顺序定义为逻辑顺序;二是总线上请求发生的顺序,我将这种顺序定义为物理顺序。然后再针对发生自修改代码的两种情况分开讨论,何时遵从逻辑顺序何时遵从物理顺序。
先说DMA的情况。DMA何时会发生呢?在本系统内,系统总线的优先级由总线控制器上DMA0-7的顺序决定,I cache接在DMA0,有最高的优先级,D cache接在DMA1,优先级次之,然后才是各种DMA设备。因此DMA设备的优先级教两个cache要低,也就是说,DMA请求只有在两组cache均命中时才能抢占总线与内存通讯。因此DMA请求发生的时机实际上很难去推断,很难分析系统总线何时会空闲能够让DMA设备占用,这也就是说,我们无法确定DMA请求与当前cache中的请求之间的逻辑顺序。因此,系统在处理DMA请求引起的cache同步时,遵从的时物理顺序,只要监听到总线上有来自其他设备的写请求,就自动进行同步,在物理顺序上保证从cache中取出的数据时最新的。
再说说由Store X指令引起的自修改代码。在本系统内,有一条5级的流水线,MEM级在流水线更深的地方,这就意味着当MEM级执行着的store指令引起了I cache的同步,若I cache中正在取这个地址上的指令,这个指令逻辑上应该在store指令完成后再被预取。因此对于由store指令引起的自修改代码,本系统遵从逻辑顺序,即保证发生这种情况时,I cache中取出的指令是Store指令新存入的指令。
cache同步与其他流水线控制事件同时发生
这个问题是我这一个多月着重思考的问题,在这篇文章里我先说一下在IF指令预取这个阶段可能同时发生的流水线控制事件以及处理方法。
IF级可能发生分支预测失败、IF级异常(如TLB、地址错误)、自修改代码。他们如果同时发生,优先级如何确定,谁必须先处理?
经过缜密的思考,我这里提出在处理流水线控制事件时的两条原则:
- 绝对不能丢失正确的处理顺序
- 异常不能被错过
异常会保存当前引起异常的指令的地址,并跳转至base;分支预测失败需要跳转至正确的目标,不需要保存地址;自修改代码(SMC)则需要重新读取当前地址,也不需要保存地址。下面分析他们三个之间的优先级。对于第一条原则,我们要做到无论怎么去处理这些事件,都要保证正确的处理顺序不被丢失,例如如果在异常和分支预测失败同时发生时,选择处理异常,由于当前的异常并不是正确的将要处理的指令,因此处理异常会丢失当前ID级正在执行的跳转指令产生的正确的跳转目标,这应该是不允许的。对于第二条原则,由于处理器会暂停,尤其是写后读和多周期会只暂停IF和ID级,要保证在处理器暂停时,其他异常不能被错过,就要保证异常只和流水线寄存器有关,当流水线寄存器变化时,各种异常信号变化,当流水线寄存器不变时,各种异常信号保持。
根据这两条原则,我确定分支预测失败的优先级最高,当他发生时,npc设置为正确的跳转目标,不保存EPC,撤销当前IF。EXC的优先级紧随其后,npc设置为base,保存EPC并撤销当前IF。SMC的优先级最小,这是因为前两者发生时,IF级中的内容会被废弃,cache的同步在cache内部自动进行。
本平台使用的总线控制器是一个非常简单的装置,其内部的状态机也十分简单,并不能实现撤销已经向总线上的设备发送的请求的功能,因此要想实现这些优先级,我们还需要在cache同步机制中增加正确的撤销机制,保证已经送出的请求不被撤销,等待其执行完毕。
cache同步机制的设计与实现
同步机制
同步机制是由总线监听完成的。
首先,引入一组寄存器,持续不断地监听总线上的写请求。这里需要特殊说明的是,除了要监听写请求,还要监听自己的总线允许信号,这样就可以将自己的请求排除在外。如果不在监听时排除自己的请求,就会使系统陷入自己的写请求,需要同步,又有自己的写请求,又需要同步……这样的死循环。
1 | //BUS_addr_reg registered the address bus |
这些寄存器在clr为高电平时清零,无视系统的stall信号,在每个时钟上边沿寄存总线上的请求。这意味着cache对总线的监听持续不断,cache内部的更新持续不断。
1 | always @ (posedge clk) |
然后,从监听得的总线地址中切片出索引和标签,供比对使用。
1 | //sync index from the BUS or BUS register |
接下来需要修改TAG,为TAG增加一个读接口,和总线上监听得的请求对比,判断当前地址是否已经在cache中。
1 | //Out put registers for bus sniffing. |
这里值得说明的是,对于TAG_X_sync_out所使用的索引是直接从总线的地址线上接过来的而不是监听寄存器中的结果,这样做的原因是之前提到过的,altera FPGA板载的存储接口上由内置的寄存器。这样的设计使得在时钟上升沿到达后,TAG_X_sync_out中所保存的标签和监听寄存器中保存的标签对应着同一时刻。
在获得监听结果后,就要进行比对,判断总线上的写请求是否存在于cache内。
1 | //cache_sync signal is HIGH when the sniffed request from the bus is cached. |
可以看到,这里的同步信号cache_sync_X使用了前面所说,只在有其他设备的写入请求存在在cache中时产生高电平。
如果某一组同步信号为高电平,意味着cache将在下个时钟上边沿到来时清零对应的valid bit。
那么如果当前监听到的请求和当前cache的请求时同一地址,清零对应的valid bit要在下一个时钟上边沿到来时才发生,此时如果cache命中怎么办?这时我们依据上一节对自修改代码事件的顺序的讨论,确定这套机制的行为。如果监听到的请求是某一DMA设备发来的,则我们应当依照物理顺序,认为当前的cache的请求发生在DMA请求之后,即应当屏蔽掉当前的cache命中信号,保证cache读出的是新内容;如果监听到的请求时D cache发出的写请求,则我们应当依照逻辑顺序,认为当前的cache请求发生在监听到的写请求之后,即也应当屏蔽掉当前的cache命中信号,保证cache读出的是新内容。两种情况的处理方法一致,这是巧合吗?这与之前我们所定的原则有关,那两条原则确定了这样的行为。
因此我们要按照两种不同的情况产生对应的valid bit清零信号:
- 监听到的请求与当前cache的请求是不同地址
- 监听到的请求与当前cache的请求是相同地址且cache读命中
对于情况一,由于同步操作不影响cache当前的请求,因此直接依照同步信号生成对应的清零信号。
对于情况二,我们不仅要产生对应的清零信号,还要屏蔽当前的假的cache命中信号。因为产生的清零信号要在下一个时钟上边沿到来时才生效。
1 | //VALID_X_clr is HIGH when we need to clear the valid bit. |
同时将HIT_mask加入CACHE_HIT_R的条件
1 | wire CACHE_HIT_R = NO_CACHE ? HIT_C : (HIT_A|HIT_B) & ~HIT_mask; |
最后要修改valid bits,使其在相应的清零信号为高电平时清零。
1 | always @(posedge clk) |
值得注意的是,清零信号使用的索引是经过寄存器的结果。
撤销机制
由于我所设计的总线和总线控制器的限制,无法撤销已经向总线上的设备送出的请求,而CU会向cache发送撤销请求,撤销请求在cache内部必须根据cache是否已经向总线发出请求来判断撤销信号的行为,因此引入了撤销机制。
首先,引入一个状态寄存器req_sent,用来记录当前指令周期内,向总线的请求是否已经发送。
1 | //The bus controller we used here is a simple controller, it can't handle |
每当新指令到来时(~CPU_stall),该寄存器清零,使用BUS_grant作为向总线发送请求的标志。
然后修改BUS_req信号,使得在请求尚未在总线上发送时可以根据外部信号(cancel)撤销总线请求。
1 | //BUS request can be canceled if the request hasn't been sent |
最后,修改cache的ready信号,当总线请求被成功撤销时(cancel & ~req_sent),cache直接准备好。
1 | always @(*) |
cache同步机制的测试
由于同步和撤销机制是在原有设计的基础上添加的功能,因此在修改后,我首先运行了原有的测试程序,测试原有的功能有没有问题。经测试,原有的设计功能没有发生变化。然后我针对新功能进行了测试。测试的方法是修改测试程序cache_t.v将其中的请求地址序列进行相应修改。
将I cache的请求序列修改为:
1 | begin |
将D cache的请求序列修改为:
1 | reg [31:0] exe_address [0:7]; |
可以看到分别测试了周期1 对地址0写入时引起的与当前I cache请求地址相同的同步事件,和周期5对地址4写入时引起的与当前I cache请求地址不同的同步事件。
测试结果如图: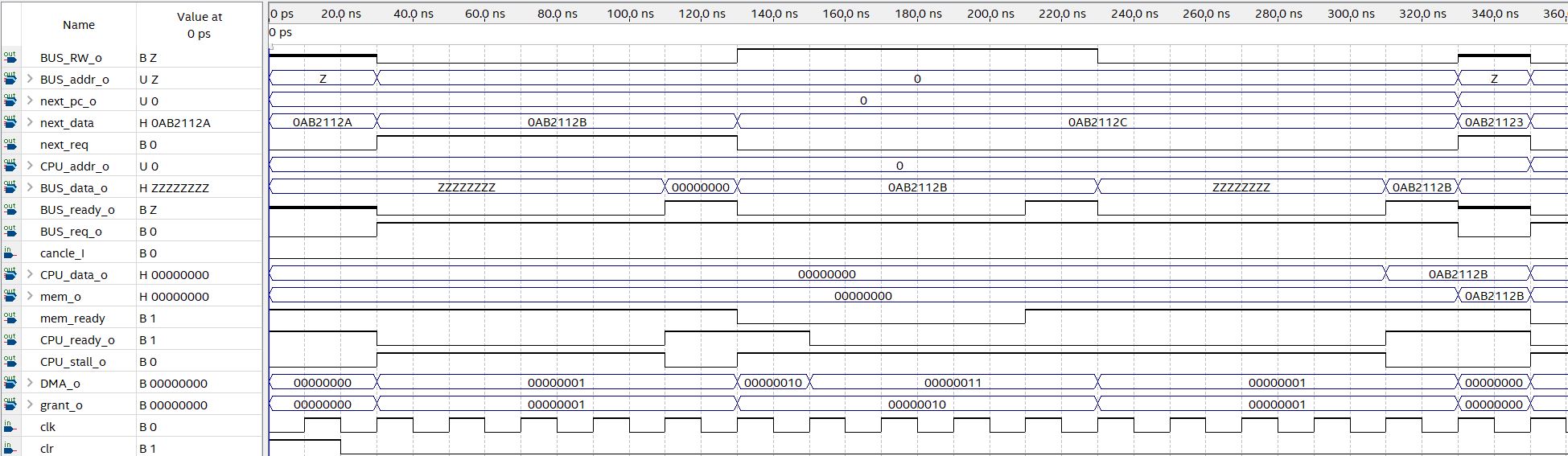
由图可见:
110ns,I cache读取完地址0,CPU准备完毕,进入下一请求。
130ns,由于I cache命中导致总线让给D cache写入地址0,I cache在下一时钟监听到该请求,撤销了命中信号,重新请求总线得到写入的新内容
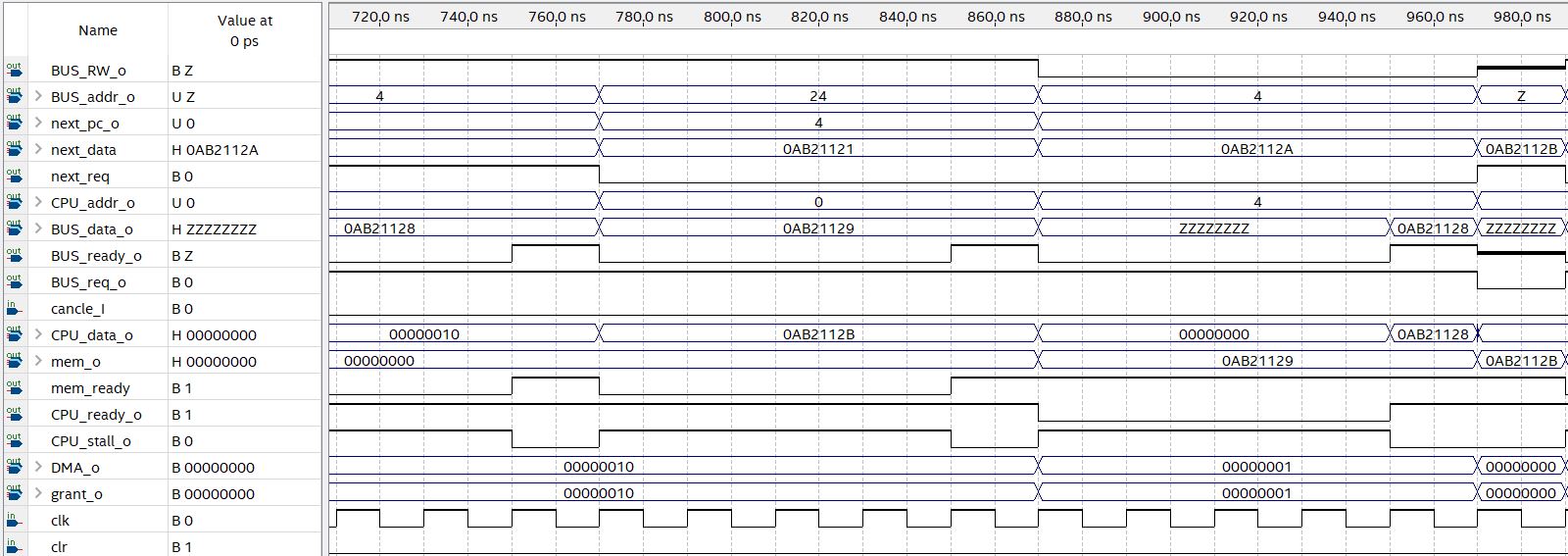
由图可见:
430ns,由于I cache之前读过地址4,使得这次读取cache命中。
670ns,D cache向总线发起写请求,写地址4,这应当出发I cache的同步机制。
870ns,可见I cache再次读取地址4,没有命中,说明同步机制起作用了。
对于撤销机制的测试: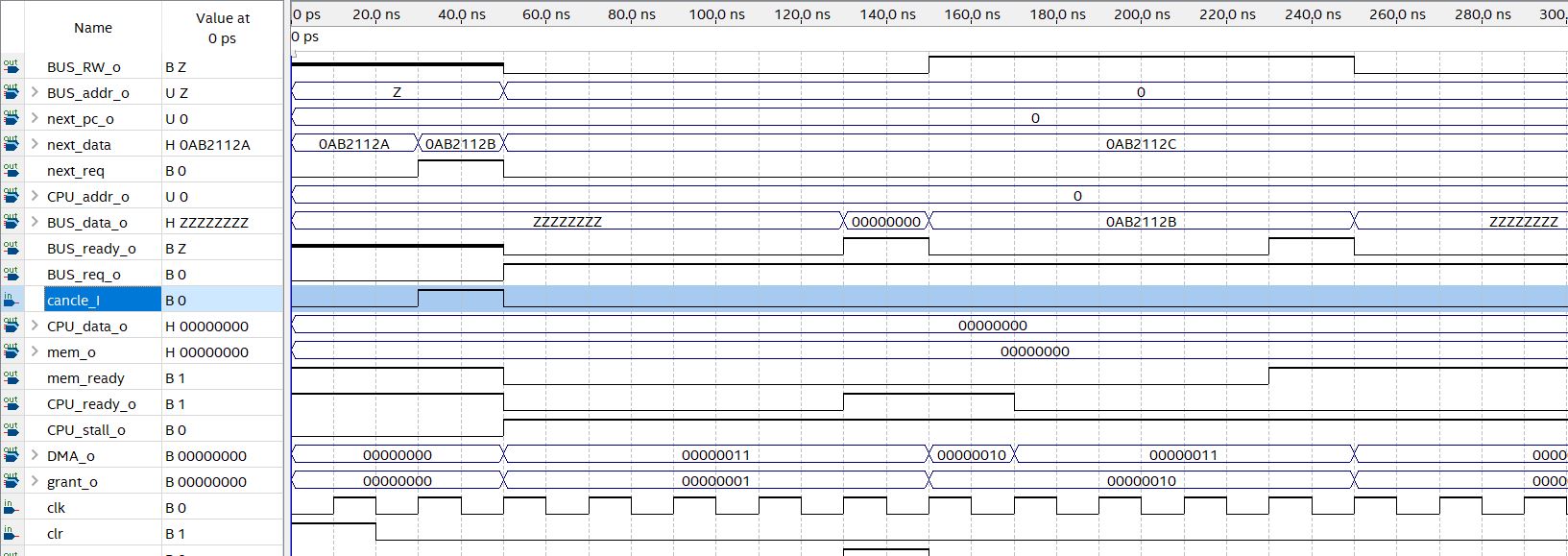
在30-50ns引入cancel信号,可以看到由于当前对总线的请求尚未发送至各设备,因此该请求成功取消。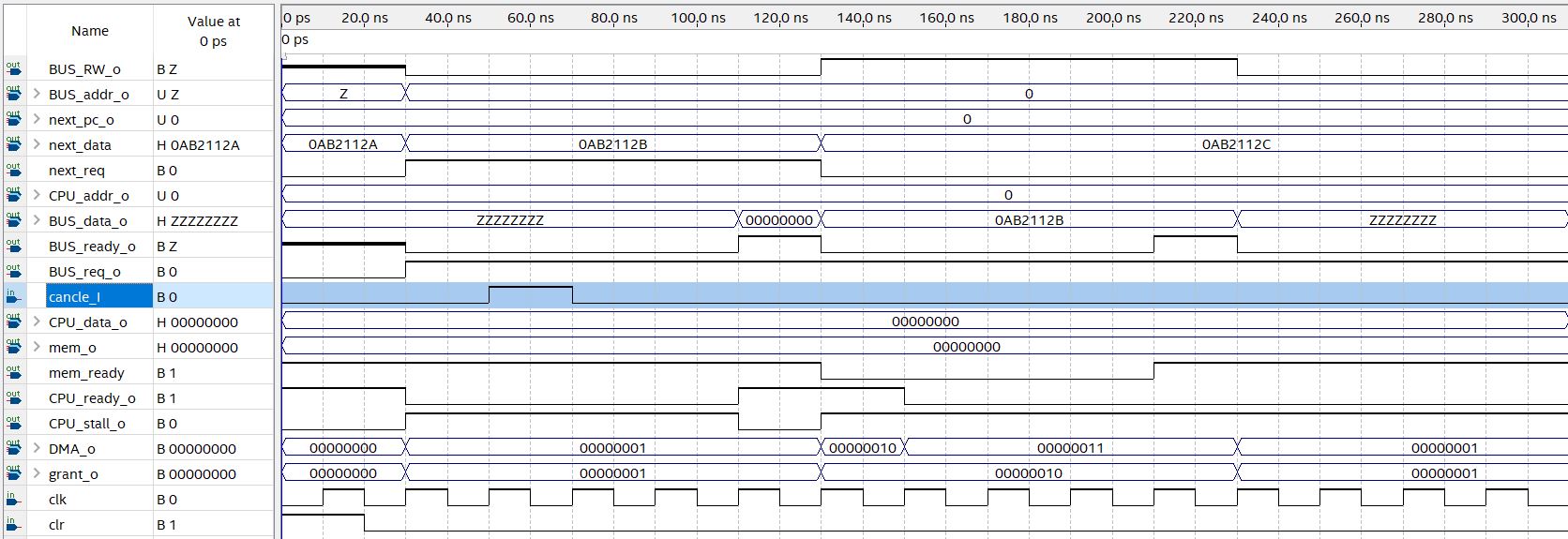
而若是在50-60ns引入cancel信号,由于在50ns的时钟上边沿已经将总线请求发出,因此不能撤销当前的请求,必须等待当前请求执行完毕。
小结
当前的设计,只是一个初步的设计,因为后续的流水线控制还没有最终敲定。
在设计和验证的过程中出现了一个小问题,就是我使用的quartus lite版本,竟然在仿真时提示我脚本过长,超过了免费版本的限制,它因此故意将仿真速度进行了限制。
已知问题
由测试1可以看出,该同步机制,对于总线有要求,要求一个总线事务至少两个周期,第一个时钟上边沿各个设备接受请求,第二个上跳沿各个设备发送准备好信号。否则的话,不能完成所要求的同步与当前cache请求相同的地址的要求。