本项目所设计的CPU,与李亚民书中所描述的CPU主要区别是在MIPS CPU中引入了微代码,方便指令集的扩展、编译器的移植和系统编程。
带有微指令的IF级
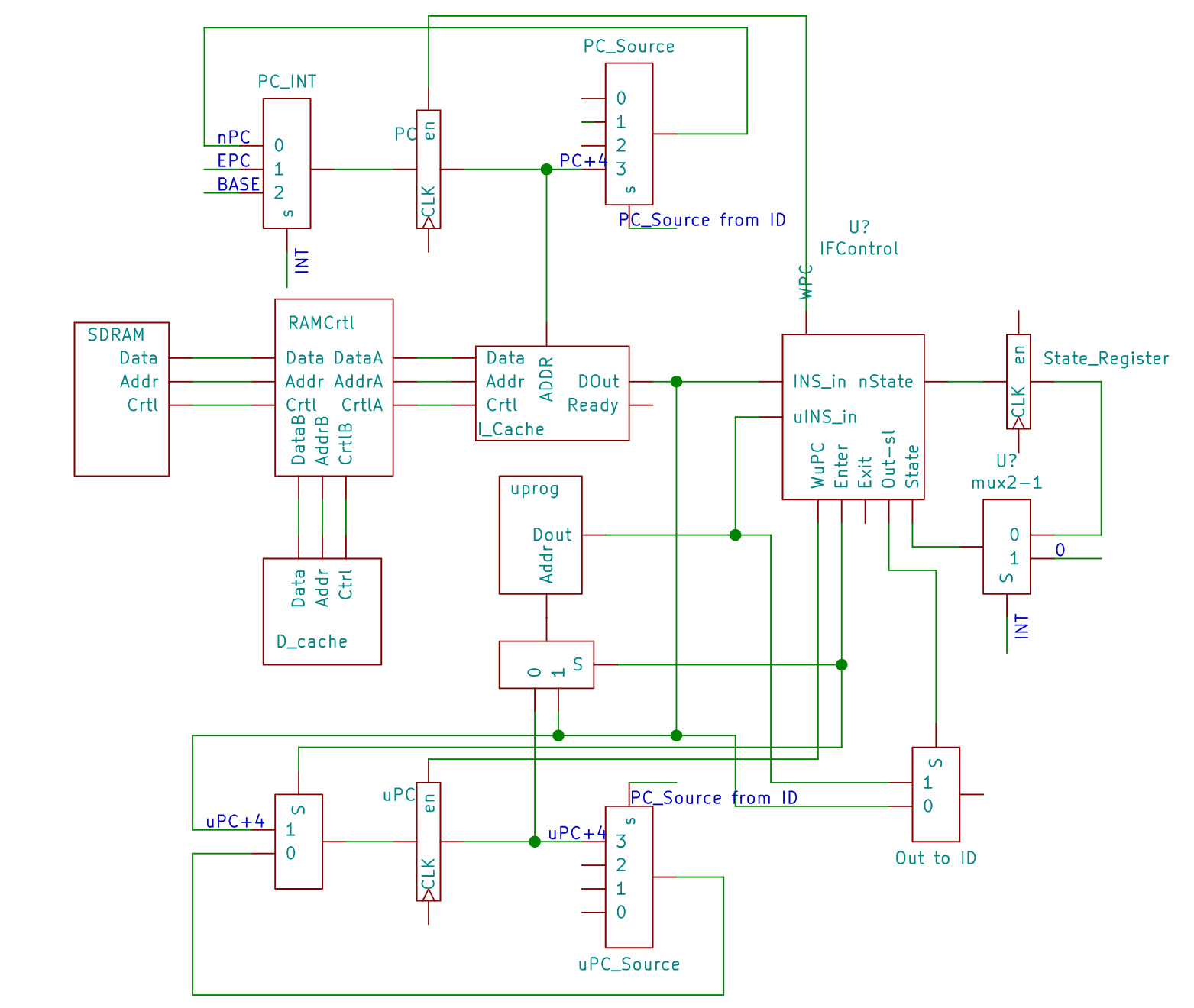
由原理图可知,主要的修改是加入了:
- 微指令存储器 uprog
- 微指令寄存器 uPC
- 下一个微指令选择器
- IF控制器 IF Control
- 状态寄存器 State
微指令存储器的结构
本平台使用的微指令有如下结构:
classDiagram
class MicroCode{
head 1
head 2
......
head n
code1 ()
code2 ()
coden ()
}
class Head{
a JUMP instruction
first op in the code section-delay slot
}
微指令存储器包括两个部分,头部按照指令号寻址,按顺序存放在存储器中。每个头部域有两行,第一行是一个跳转指令,跳转到对应的代码域,第二行是为了满足延时槽的特点,将代码域的第一行代码放置在延时槽中。
由于微指令的头部有两行,所以在使用指令中的指令号作为地址对微代码存储器寻址时,要先向左位移一位。
如此设计微指令存储器,可以方便寻址,并且最大限度地利用微指令存储器的空间,头部和代码之间没有分割。
微指令存储器的代码域由一个终结指令分割。这个终结指令供IF控制器判断一个微指令是否结束。代码域中可以使用任何一条用硬线逻辑实现的指令,一旦进入微指令状态,微指令中的跳转指令将只修改微指令计数器uPC。每个微指令代码域的最后一条指令(终止符前)不能是跳转指令。
微指令工作过程
在不考虑中断或异常的情况下,整个IF阶段实际上分为两个个状态:
- 正常状态
- 伪指令状态
与此同时,还要判断两个动作:
- 正常状态–>微指令状态(enter)
- 微指令状态–>正常状态(exit)
IF的状态由State Register记录,动作由state和正在输入的指令(INS_in, uINS_in)判断。
| 状态转换 |
State |
nState |
INS_in |
uINS_in |
wpc |
wupc |
enter |
out_sl |
| n->n |
0 |
0 |
0 |
x |
1 |
0 |
0 |
0 |
| n->u |
0 |
1 |
1 |
x |
1 |
1 |
1 |
1 |
| u->u |
1 |
1 |
x |
0 |
0 |
1 |
0 |
1 |
| u->n |
1 |
0 |
0 |
1 |
1 |
1 |
0 |
0 |
| u->u |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
上表中,表头对应原理图中的信号。state=0表示正常状态,state=1表示进入微指令状态。nState表示下一个状态。INS_in=0 表示当前指令以硬件方法实现,INS_in=1 表示当前指令是以微指令方式实现。uINS_in=0表示当前微指令不是结束符,uINS_in=1表示当前微指令是结束符。wpc和wupc分别控制pc和upc的写入使能。
enter为进入微指令状态时的指示信号,为了提高ipc,一旦发现一条指令时使用微指令实现的,就应当直接输出对应的微指令,所以进入微指令状态需要额外处理:微指令存储器的地址直接由enter信号选择为指令中的地址位,微指令存储器输出head中对应的跳转指令,下个时钟周期到来时,该地址+4放入upc,微指令状态延时槽仍然保留。之后的upc由ID阶段的upcSource更新。
out_sl标志输出是微指令存储器内的内容还是指令cache中的内容。当状态发生转换时,n->u时,若将指令cache中的指令直接传入ID,ID是无法识别的,这个时候因为enter信号的作用,使得该指令对应的微指令已准备好,所以out_sl为1,即当微指令实现的指令出现时,直接传入其对应的微指令。同理,当u->n时,若将微指令结束符传入ID,ID也是无法识别的,这个时候急需要使out_sl=0选择输出下一条指令。这里还有一个特殊情况,就是当下一个输入的指令也是由微指令实现的,那么实际上IF阶段再一次进入了微指令状态(reenter),这时enter信号选择了新的微指令地址,向ID级输入正确的指令。
关于pc和upc的控制有些复杂,简单来说,就是消耗一条指令,就要写一次pc,消耗一条微指令就要写一次upc。所以可以看到当enter和reenter的情况发生时,等于说既消耗了一条指令,又消耗了一条微指令,所以在这种情况下pc和upc均被写入。
由于延时槽和流水线的存在,使得下一个pc和upc的值的判断变得复杂。而我的设计又希望尽可能地将修改停留在IF级,所以才把pc和upc地写入限制加在了IF级。由于ID级要计算跳转指令的目标地址,所以当前PC或者uPC要传入ID级。改进的IF级中,nPC和nuPC的两个多路复用器,除了+4这一项输入分别对应pc和upc自身外,其余三个输入是相同的,均由ID级直接给出,选择信号也是相同的,也由ID级直接给出。这样做的好处是对于ID级不需要做任何修改,就能实现在微指令状态中的跳转修改upc,而在正常状态下的跳转指令修改pc。考虑下面几种情况中pc和upc的变化。
| 存储器位置 |
情况一 |
情况二 |
情况三 |
| 01 |
硬件实现指令(非跳转) |
跳转指令 |
硬件实现指令(非跳转) |
| 02 |
微指令实现指令 |
微指令实现指令 |
微指令实现指令 |
| 03 |
硬件实现治指令 |
跳转指令的目标 |
微指令实现指令 |
情况一是比较正常的情况,pc=01,该指令是一个硬件实现指令,所以直接输出,这时候向下一级输出PC。下一个时钟到来,若当前指令是延时槽中的指令,pc等于其目标;若当前指令不处于延时槽中,则pc=pc+4。若跳转的目标是一条普通指令,这种情况比较正常,不涉及到状态切换,在这里不考虑。
当pc=pc+4 或者当前指令是延时槽中的指令,并且跳转的目标刚好是02,这时候要发生状态切换。此时01指令已在ID级,它不是跳转指令,所以pc_source被ID级设置成pc+4。而此时是enter的情况,所以upc被设置成指令中所知的位置,而upc_source和pc_source公用一个信号,所以upc_source也被设置成upc+4.当 下一个时钟周期到来时,由微指令存储器指出的微指令被送入ID,而pc和upc分别被写入为03和微指令头部延时槽的地址。并且IF级向ID级送入upc,供微指令中的跳转指令参考。
当微指令执行结束,也就是upc指向了一个终止符。这时上一条指令(ID级中的指令),由于一定不是跳转指令,所以会把pc_source设置成pc+4,准备向ID级输出pc所指的指令03。下一个时钟到来,upc+4,pc+4=04,而upc指向结束符的下一个指令,脱离结束符的状态。
情况二比较特殊,02位置的指令是一个延时槽。我们考虑这种情况下upc和pc如何变化。pc=01,该指令是一个硬件指令,所以直接输出,这时候向下一级输出pc,此时时钟到来,pc+4=02指向微指令实现的指令。由于ID级是跳转指令,所以ID级将pc_source设置成响应的跳转目标,这里是03。所以时钟到来后,pc=03,upc为指令中所指示的地址+4。可以看出,这种情况实际上和上一种情况是等价的,只是看起来比较特殊。在微指令执行结束后,exit情况也同上一种情况等价。
情况三考虑重进入这种情况。pc=01该指令是一个正常的指令,与情况一相同,在这就不详细分析了。考虑重进入的时刻,将02所代表的微指令送入ID时,pc已被设置为03,此时02中的微指令执行完毕,upc指向终止符,由于此时ID级一定不是跳转指令,因此pc_source被设置成pc+4,由于是重进入,当时钟到来时,IF会选出03所指的微指令中的跳转指令,并将upc设置为03中指令所指的位置+4(微指令头部的延时槽),同时会将pc设置为04.
由对上述三种情况的分析可以知道,我所设计的微指令系统时可以正常工作的。对这些情况的分析是多余的,是因为npc和nupc的值是由ID级的指令决定的。ID级是硬件指令,IF正在处理微指令,这种情况(enter)upc是特殊处理的,并不会影响pc的更新。同理ID级时微指令,IF级正在处理硬件指令,这种情况下upc和pc都直接加4,upc+4后跨越了终结符,其值在下一次进入时在被更新。其余的情况ID级时硬件指令,IF级也是硬件指令或者ID级是微指令,IF级也是微指令,这两种情况与未加入微指令系统的情况相同,只是选择性的对pc和upc的写入进行使能控制。
微指令系统对精确中断的影响
在流水线中实现精确中断并不是一件容易的事,尤其是在有分支、有延时槽的情况下。所以笔者不打算采用列举各种情况来分析引入微指令对精确中断的影响,而是试图从更高的层面去思考这个问题,以对终端系统进行针对性的修改。
中断和异常会在ID级或者EXE级到来。ID级的异常,可以是硬件中断,未实现的指令或者是系统调用systemcall。EXE级的异常可以是算术指令的溢出。
该微指令系统对原有精确中断的兼容性分析
分析引入微指令对精确中断的影响,要分析IF阶段的取指结果,和那些因素有关。如果中断到来,所保存的现场能够在恢复时确保取出的指令是正确的,那么引入微指令对中断就是兼容的。
时钟到来时,存入IR的指令与下面因素有关:
- pc的值
- upc的值
- IF的状态state
初看上一张的真值表,可以发现存入IR的指令还和当前指令是否是硬件实现的,和当前微指令是否是结束符有关。但如果考虑存储器中的内容在是固定的(对于指令和微指令而言,存储器的内容都是固定的),那么当前指令和当前微指令均是由pc和upc决定的。
也就是说,只要保存pc、upc和state,在恢复时就可以恢复这一个时钟到来时所取的指令。
而精确中断的机制,就是根据发生异常的位置,保存中断返回地址取指时的IF状态,因此,对原有终端系统的修改,只需要将过去只保存PC,改为同时保存PC、uPC和state即可。
中断到来对取指的影响
如果没有中断机制,IF级的状态转移如上一节的表格所示。但是中断机制的引入使IF级变得更加复杂。
中断相当于强制跳转并保存现场,也就是说中断到来时应当强制更新pc的值。但是IF级所取的下一条指令是由上文所说的pc,upc以及state决定的,而ID给出的中断信号,只能改变PC_INT多路器的选择信号。由此可知,上文中的状态转移过程,若wpc是1,则中断来临时,pc会在时钟到来时更新到中断向量所指的位置。
但有一种特殊情况,若此时IF级处于微指令状态,state=1,并且下一条微指令不是终结符,那么wpc=0,则pc在时钟到来时不会更新为中断向量所指的地址。这会造成错误。
再考虑IF级的输出。IF级输出也由pc,upc以及state决定,如果只对pc进行修改,使得pc在中断来临时强制修改,仍然不能使得中断向量正确向ID级传送。
所以作者在状态寄存器向IF控制器的输入处增加了一个多路器,在中断到来时强制设置state=0,但又不修改state寄存器的内容,让原有的state寄存器内容可以向下传递,使中断控制电路可以正确的保存中断前的状态,与此同时制造enter或者normal的假象,正确处理中断时的跳转问题。
小结
这篇文章描述了该自制计算机系统中处理器使如何处理微指令的。本文所描述的方法,可以充分利用硬线逻辑控制器的速度优势,又可以提供一个完整的微指令环境对指令集进行扩充。该方法区别于在很多书中记载的微指令实现方法,不使用微指令解码来控制各个功能部件实现不同的功能,而是直接以硬件实现的指令作为微指令。一条由微指令实现的指令,像一个汇编语言中的宏,如果没有这个微指令模块,这些功能自然可以通过汇编语言的宏来实现。但是,微指令模块的意义仍然存在,经过精心调试的微指令,可以充分利用延时槽、流水线冲突避免等特性来获得比用户自定义的宏更好的性能,也可以减少系统编程时出错的概率,还可以减少可执行代码的体积。在某些必须使用多周期才能实现的硬件指令,把他转换成这样的微指令,只需要付出极少的硬件代价,并且其执行可以高效的利用流水线。
该系统实现的难点有二:
- IF级的指令选择设计
- IF级的指令选择与中断系统的结合和兼容设计
关于该系统的进一步验证,等到具体实现,会用EDA工具仿真实验,届时笔者会把硬件逻辑描述和测试用例同步更新在文章中。